What is Kinetica?
Kinetica is a database, purpose built for real-time analytics at scale. Kinetica leverages vectorized memory-first architecture with kernels that have been custom built for over a decade to deliver blistering performance at scale on significantly less infrastructure than traditional data warehouses. Using a highly-distributed, lockless design, Kinetica enables simultaneous ingestion and analysis with integrated geospatial, graph, SQL, and AI/ML capabilities. With out of the box connectors for ingest and egress, native language bindings and a rich API ecosystem, developers can leverage the tools that they are comfortable and familiar with to build and deploy advanced analytical applications. With the rapid emergence of IoT applications and the exponential explosion of data volumes, architecture teams across every industry are searching for a more cost effective and performant means to manage and analyze that data - we suggest you start with Kinetica!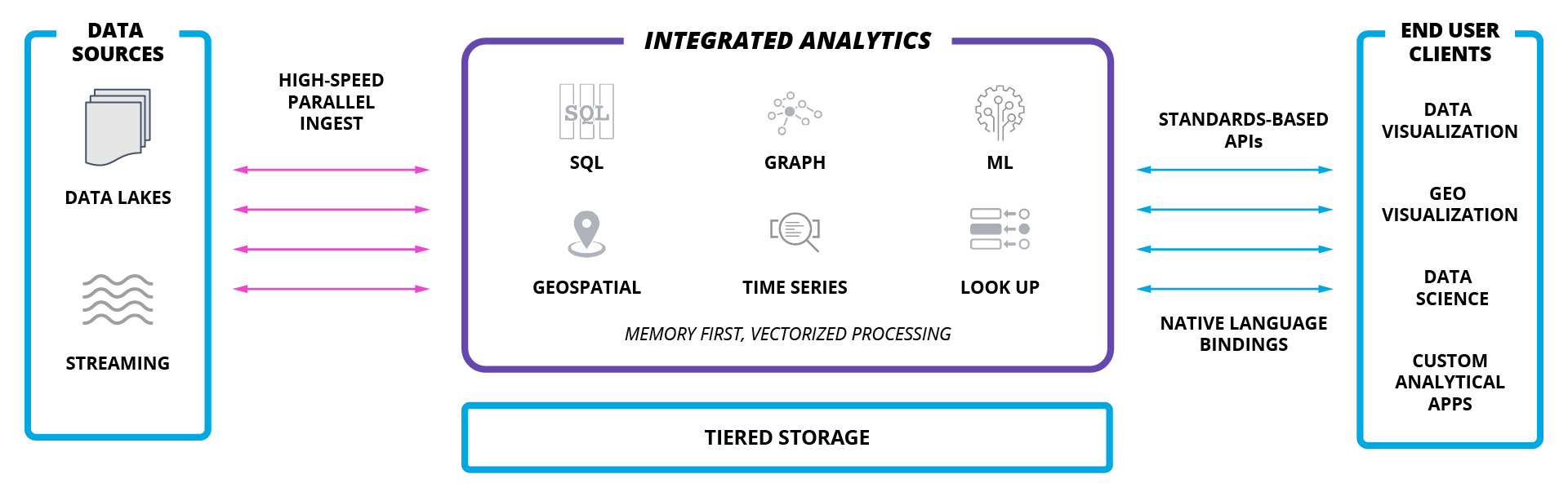
What type of data can be stored?
From a user’s perspective, data in Kinetica is organized in a manner similar to a standard relational database management system (RDBMS). A Kinetica database consists of tables, each contained by a schema. The available column types include the standard base types (int, long, float, double, string, & bytes), as well as numerous sub-types supporting date/time, geospatial, and other data forms. The native API interface to the system is that of an object-based datastore, with each object corresponding to a row in a table.What operations are provided?
Kinetica provides basic functionality to create tables, add rows, read rows, and delete rows. What really separates Kinetica is its specialized filtering and visualization functions. These functions can be performed through our native API or our ODBC/JDBC connectors, which are SQL-92, SQL-99, & SQL:2003 compatible. This allows users to integrate Kinetica with third-party GUIs and developers to quickly integrate existing code with Kinetica.How it works
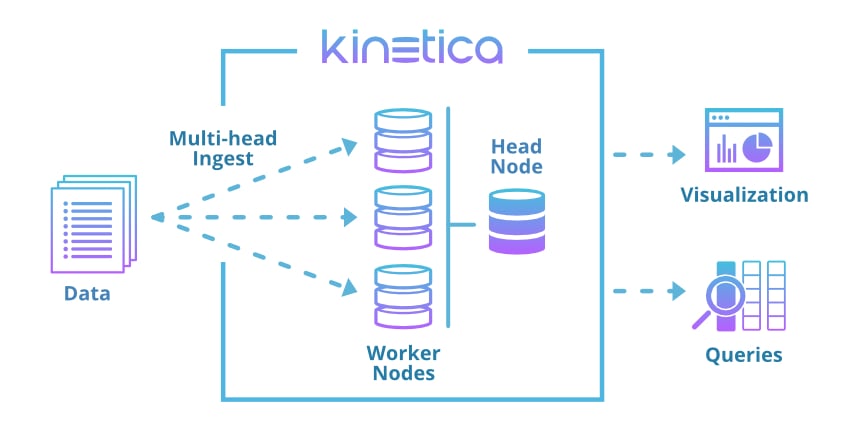
Distributed Architecture
Kinetica has a distributed architecture that has been designed for data processing at scale. A standard cluster consists of identical nodes run on commodity hardware. A single node is chosen to be the head aggregation node.