Note
This documentation is for a prior release of Kinetica. For the latest documentation, click here.
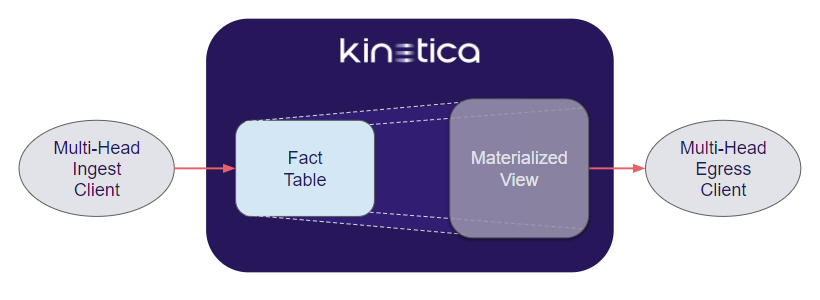
A common, highly-performant use case for Kinetica is multi-head ingest into a fact table and multi-head egress from a materialized view created from that fact table, periodically refreshed at some interval.
The example given below can be downloaded & run to demonstrate the use case on a local Kinetica instance.
This guide will demonstrate a simple use case, implemented in Java & SQL, consisting of four entities:
- Multi-Head Ingest Client
- Fact Table (ingestion target)
- Materialized View from Fact Table (egress source)
- Multi-Head Egress Client
Multi-Head Ingest/Egress
These components work together in four phases:
Setup Phase
First, a schema needs to be created to contain the other database objects subsequently created.
| |
| |
A table, order_history, needs to be created before ingestion can begin. It serves as the multi-head ingestion target.
The table is sharded on store_id, so that the subsequent aggregation on store_id by the materialized view can execute quickly, without having to synchronize aggregation results across shards.
| |
A materialized view, store_sales, needs to be created before keyed lookups can begin. It serves as the multi-head egress source.
The materialized view aggregates each store's total sales by date from the order_history table, grouping on store_id and the date portion of the order timestamp. It also uses the KI_HINT_GROUP_BY_PK hint to make a primary key out of these two grouping columns. Doing so automatically creates a primary key index on the two columns, meeting the keyed lookup criteria that all columns involved in the lookup be indexed.
The refresh interval given to the materialized view is for reference only; in this example, the view will be manually refreshed to allow results to be shown immediately.
| |
Ingest Phase
The BulkInserter is the Java object that performs multi-head ingestion. To create one, the database connection is used to extract the Type schema of the ingest target table and the BulkInserter created with that Type.
| |
Once the BulkInserter has been created, GenericRecord objects of the given Type are inserted into it. The indexes used in assigning column values to each GenericRecord are 0-based and match the column order of the target table: store_id, id, total_amount, and then timestamp.
| |
The BulkInserter automatically inserts records as each of its queues reaches the configured queueSize. Before ending the ingest session, the BulkInserter is flushed, initiating inserts of any remaining queued records.
| |
Tip
See the ingest method of MultiHeadUseCase.java for details.
Refresh Phase
Though the materialized view in this example (and in the associated use case) is configured to periodically refresh, a manual refresh is done between ingest & egress phases to avoid having to wait for the refresh cycle.
The manual refresh requires only a database connection in order to be initiated.
| |
Tip
See the refresh method of MultiHeadUseCase.java for details.
Egress Phase
The RecordRetriever is the Java object that performs multi-head egress. Creating one requires steps similar to creating a BulkInserter. The database connection is used to extract the Type schema of the egress source table and the RecordRetriever is created with that Type.
| |
Multi-head egress is accomplished through a keyed lookup of records. At this point, the lookup keys & filters are established.
The lookup filter is fixed to the current day's date.
| |
The lookup keys are established, one for each store number being looked up. Each key value is matched against the shard key column, store_id, of the source view, store_sales. Since the view has only one column in its shard key, there is only one entry in each key List.
| |
With each store number lookup key and the fixed date filter for today, the RecordRetriever extracts the corresponding store sales total and outputs the store_id & total_sales. Similar to the assigning of column values with the GenericRecord during ingest, the indexes used in extracting column values from the result of the keyed lookup are 0-based and match the column order of the source view.
| |
Tip
See the egress method of MultiHeadUseCase.java for details.
Download & Run
Included below are the artifacts needed to run this example on an instance of Kinetica. Maven will be used to compile the Java program.
- pom.xml - for compiling the Java example program
- MultiHeadUseCase.java - the ingress/egress Java example program itself
To run the example, compile the Java program & run.
Create a directory for the example Java project and move the example files into it as shown:
1 2 3 4 5 6MultiHeadUseCase/ ├── pom.xml └── src/ └── main/ └── java/ └── MultiHeadUseCase.javaCompile the Java program in the directory with the
pom.xml:1 2cd MultiHeadUseCase mvn clean packageRun the example:
1java -jar target/multi-head-1.0-jar-with-dependencies.jar run [<hostname> [<username> <password>]]Verify the output consists of aggregated sales totals for each store for the current day and should be similar to the following:
Summary for date: [2018-10-01] Store # Total Sales ======= ============= 1 49920144.83 2 49924795.62 3 50096909.16 4 49986967.66 5 49987397.21 6 50250738.93 7 50280934.38 8 50145700.21 9 49807242.51 10 49875441.35