Data¶
All the data in the database can be viewed through the Data menu selection. From here, you can view detailed information about each table or collection; use WMS to generate a heatmap of a table with geocoordinates; create, delete, or configure a table; or import data.
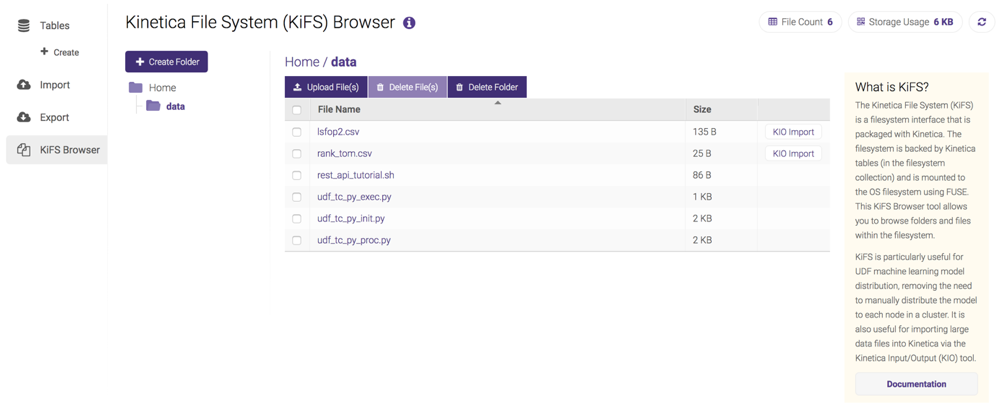
Tables¶
The Tables page lists all tables and schemas/collections in the database in a grid layout. Also available are the object type (table or collection), type of distribution (replicated, sharded, or neither), feature set (see list below), global access rights (read/write), keys (primary, shard, and foreign) and associated columns, and the record count.
The types of features are as follows:
- PERS (PERSISTED) -- the table exists on disk & in memory (i.e., not memory-only) and will exist across database restarts
- JOIN -- this is a join view
- RESU (RESULT_TABLE) -- results from endpoint operations like Create Projection and Create Union
- VIEW -- this table is a filtered data view or materialized view
From this page, the following functionality is available:
 (Refresh) -- refresh all tables
(Refresh) -- refresh all tables- Create -- create a new table
- Config -- modify the selected table
- Rename -- rename the selected table
- Move -- move the selected table(s) or view(s) to a different collection
- Delete -- delete the selected table(s)
- Rebuild -- rebuild the selected table(s) and/or collection(s)
- Memory -- display the current amount of used memory for the selected table(s); if a collection is selected, the child tables' memory will be displayed
- Stats -- display statistics regarding a selected column or all columns in the table, e.g., estimated cardinality, mean value, standard deviation, etc., and recommendations for improving the structure of the table, e.g., dictionary encoding, smaller column type, etc.
- Filter -- only display tables matching the given search text
- Sync Mode -- if enabled, table row counts will be accurate but potentially slow
- + Add Collection -- specify a name, then create a collection
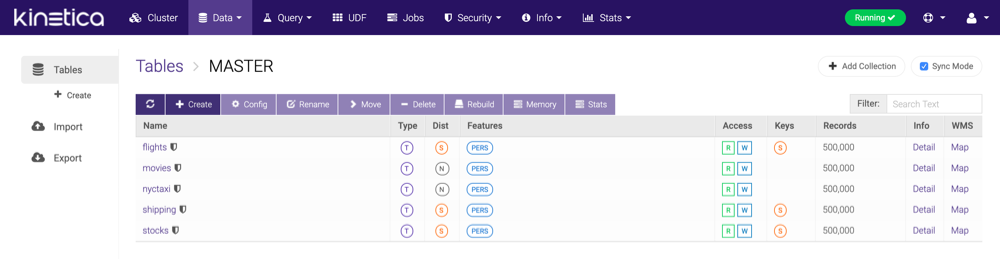
Configuring¶
To configure an existing table, click Config, update the table configuration as necessary, and click Apply. Click Reset to discard any pending modifications.
Allowed modifications include:
- Renaming the table
- Modifying the TTL
- Renaming the non-primary/shard key columns
- Modifying the type, subtype, storage, and properties of a non-primary/ shard key column
- Removing any non-primary/shard key columns
- Adding new columns
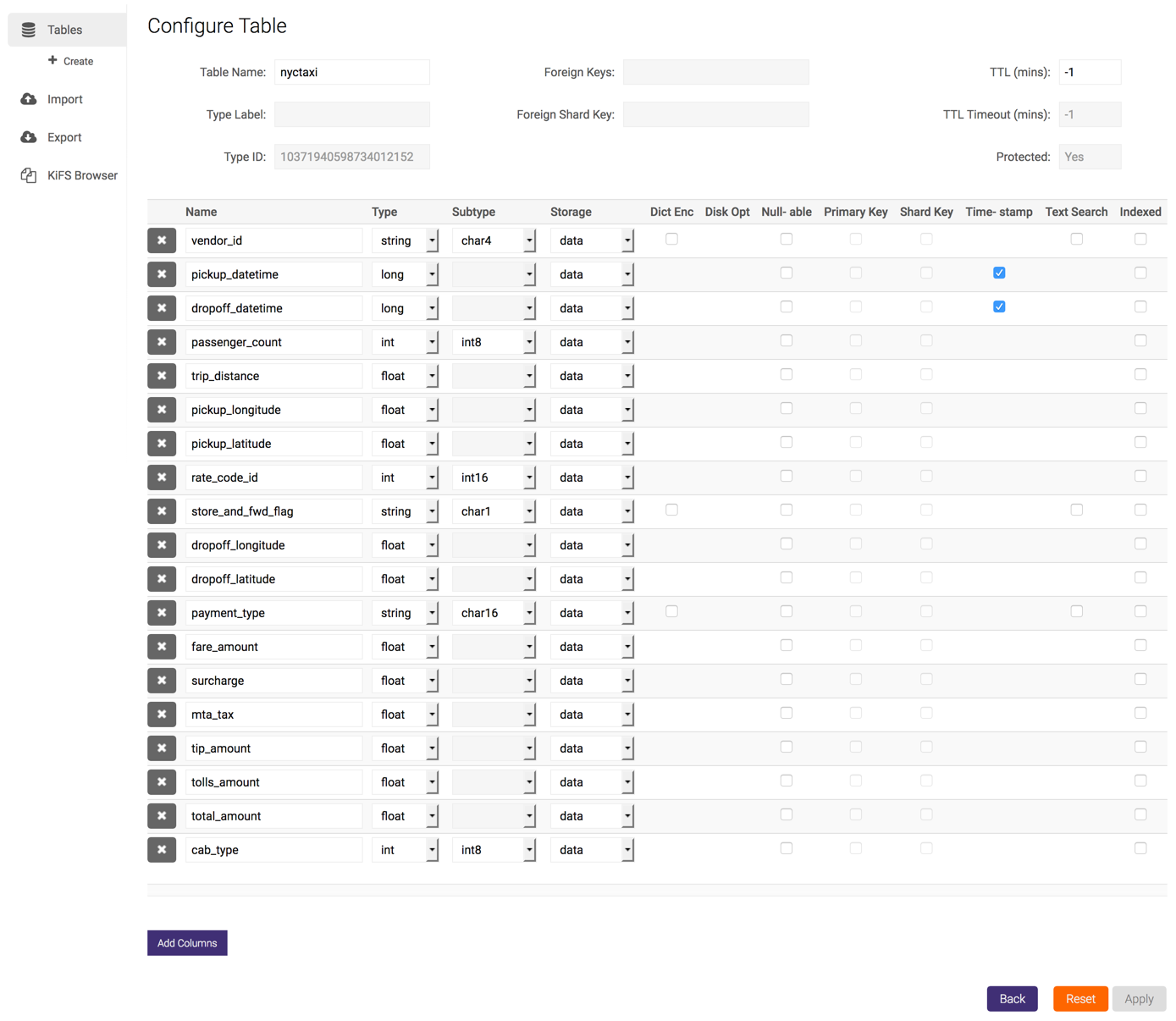
Moving¶
To move a table to another collection, select a table (or tables) then click Move. Select which collection to move the table(s) to (the blank option is the root-level collection) and click Move.
Deleting¶
To delete a table, select a table (avoid clicking the table's name, as it will open the Data Grid page) then click Delete and confirm the deletion of the selected table.
Rebuilding¶
To rebuild a table or collection if you are unable to query it, select a table(s) or collection(s), click Rebuild, then confirm the rebuild. Acknowledge the warning, then the selected table(s) and/or collection(s) will be rebuilt. For more information on rebuilding the database, see Admin.
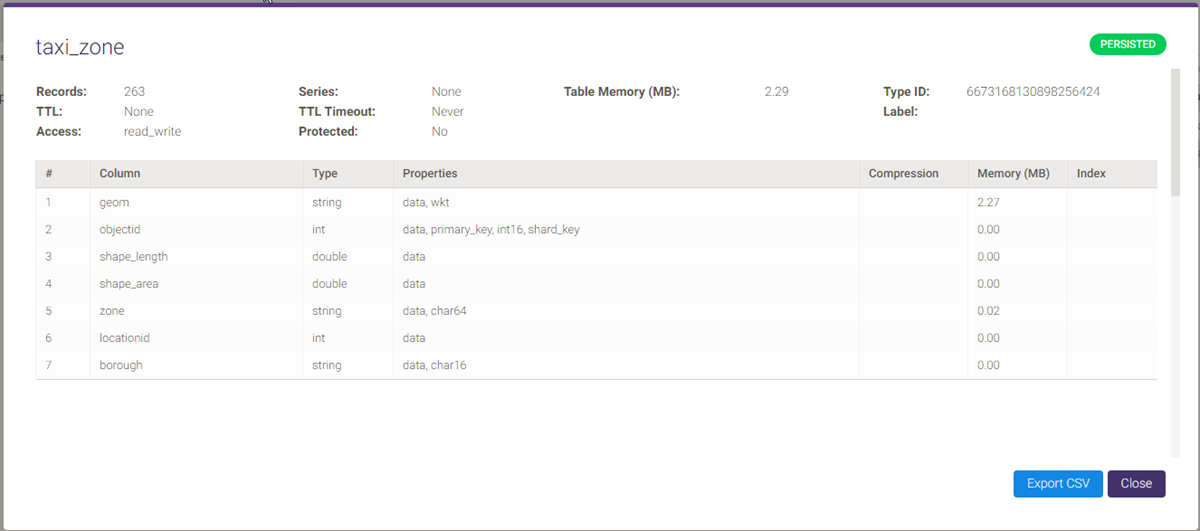
Detailed Table Information¶
To view table information, click Detail in the Info column. The column grid can be exported to CSV by clicking Export Columns CSV.
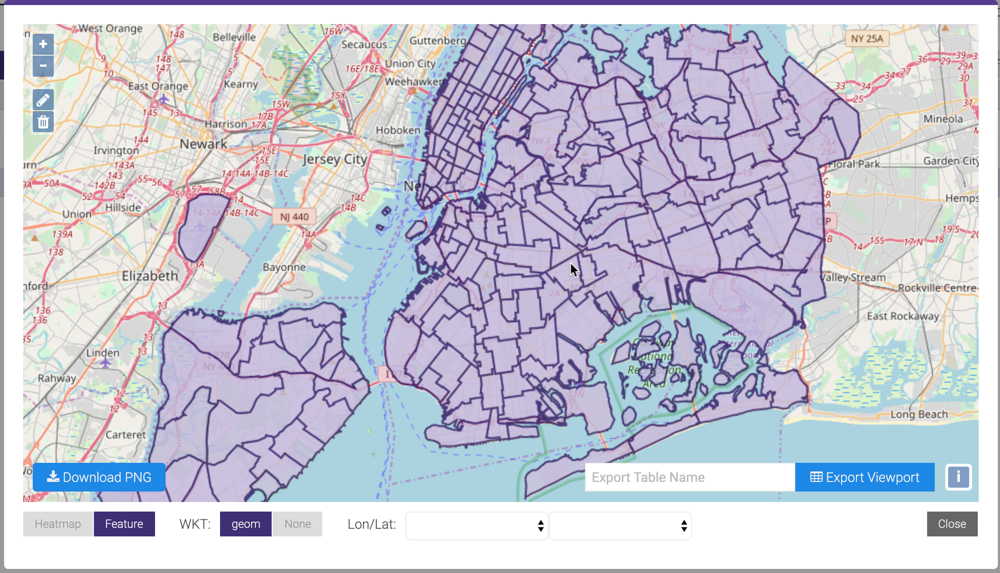
WMS¶
If your data contains coordinates and/or geometry data, you can:
- When viewing the list of tables (), click the Map link in the WMS column
- When a table's datagrid, use the WMS button in the top bar
You can use the + / - on the left or the scroll wheel
of your mouse to zoom in and out of an area. Click  to draw a polygon on
top of the map; this will act as a filter for the viewport. Click
to draw a polygon on
top of the map; this will act as a filter for the viewport. Click  to
remove any polygons on the map. Click Download PNG to download a
to
remove any polygons on the map. Click Download PNG to download a
.png file of the current viewport. Provide a table name and click
Export Viewport to export the points in the current viewport to
a separate table; note that if any polygon(s) were drawn on the
map, only the points inside those polygons will be exported to the new table.
Note
The map will default to Heatmap mode. To render full WKT geometry, click Feature.
The following column types can be used to populate the map with latitude/longitude points (assuming the columns being used to render the points are of the same type):
doublefloatintint16int8longtimestampdecimal
The following column types can be used to populate the map with WKT objects:
wktwkb
If there are multiple WKT columns, select the desired column to display next to WKT; if there are multiple longitude / latitude columns, select the desired columns from the Lon/Lat drop-down menus. If there are both WKT objects and longitude / latitude points present in a table, select the WKT column to display WKT or select None and the desired columns from the Lon/Lat drop-down menus to display longitude / latitude points.
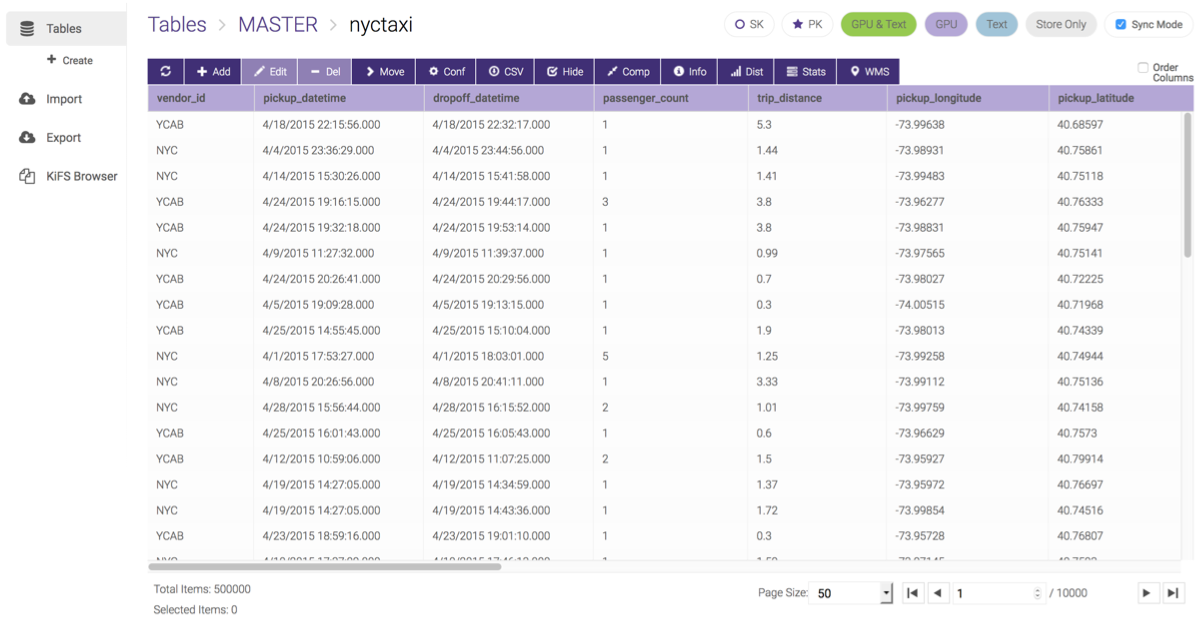
Data Grid¶
To view the individual records in a table, click the table name. This will display the data grid page. From here, the following functionality is available:
- (Refresh) -- refresh the table
- Add -- insert a new record
- Edit -- modify the selected record
- Delete -- delete the selected record
- Move -- move the table or view to a different collection
- Conf -- modify the table or view
- CSV -- export data to CSV
- Hide -- hide displayed columns within the grid
- Comp -- compress individual columns of data in memory; see Compression for details
- Info -- display table detail
- Dist -- display cross-node data distribution graph
- Stats -- display statistics regarding a selected column or all columns in the table, e.g., estimated cardinality, mean value, standard deviation, etc., and recommendations for improving the structure of the table, e.g., dictionary encoding, smaller column type, etc.
- WMS -- plot data from tables with geospatial data on a map
- Sync Mode -- if enabled, table row counts will be accurate but potentially slow
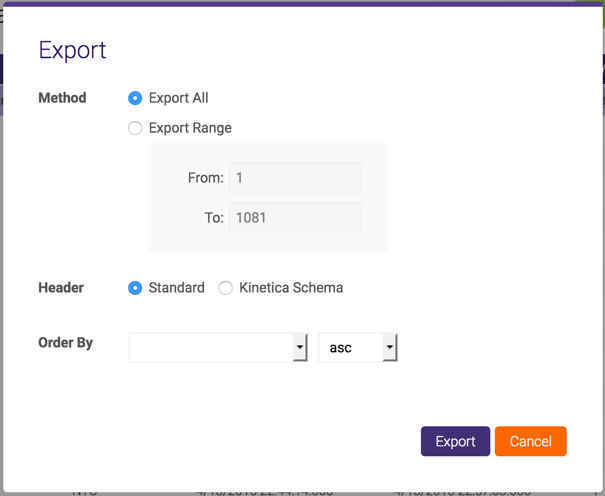
Export Data¶
From the data grid page, select CSV. You will have the option to export all of the data or records within a range, specify the type of header, and how to order the data on export.
Once you click the Export button, the data will be downloaded to your computer. The standard header is just a comma-delimited list of column header names:

The Kinetica Schema is a comma-delimited list of column headers with bar-delimited column properties:

Note
Null values are represented as \N. This can be changed by
modifying the data_file_string_null_value parameter in
/opt/gpudb/tomcat/webapps/gadmin/WEB-INF/classes/gaia.properties.
Compression¶
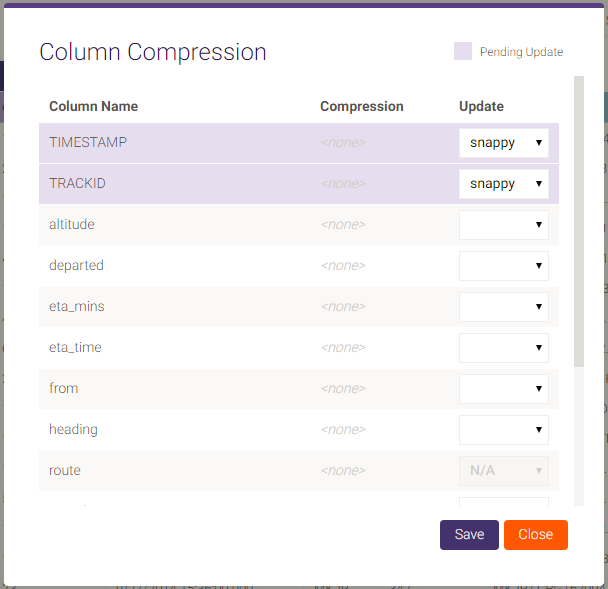
In addition to using the API or SQL to set compression, you can set it by clicking Comp on the data grid page, opening up the Column Compression dialog. Each column will be shown with its current compression setting under Compression and a selectable new compression setting under Update. After compression adjustments have been made, click Save to put those changes into effect. See Compression for more detail on compression and compression types.
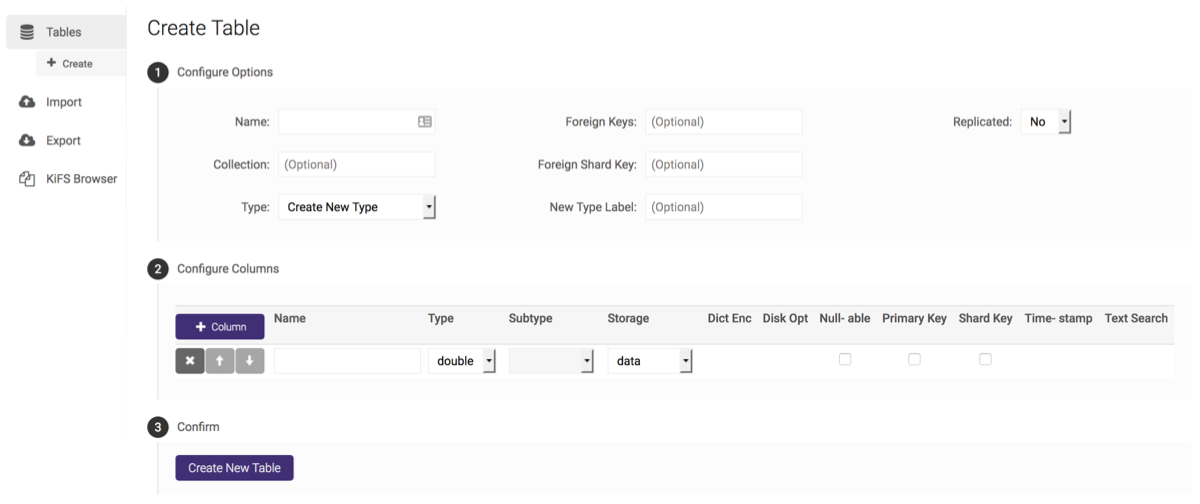
Creating¶
A table can be created by clicking Create on the left menu to navigate to the Create Table page. After configuring the name, containing collection name, distribution scheme, keys, and column set, click Create New Table.
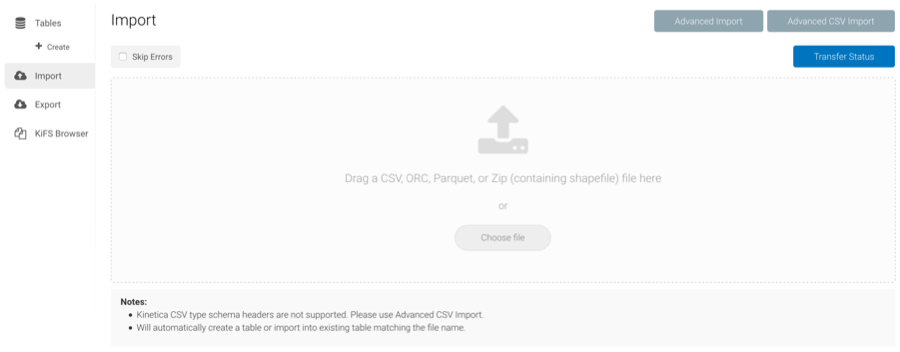
Import¶
Data can be imported from many types of files on the Import page. There are three types of import methods available:
- Drag & Drop Import -- default import method
- Advanced Import -- Kinetica Input/Output (KIO) Tool
- Advanced CSV Import -- CSV importing with additional options and control
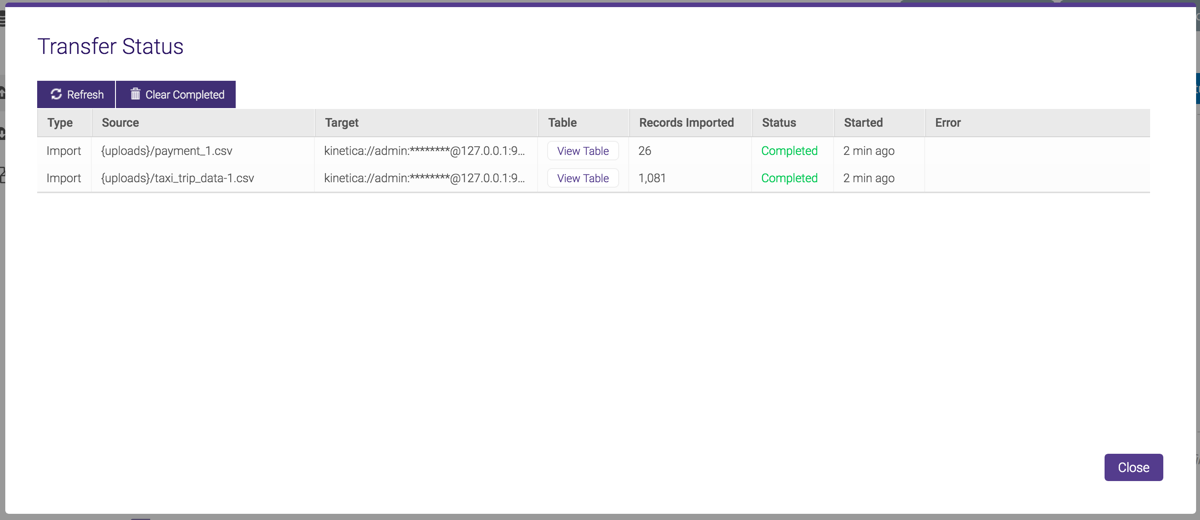
Drag & Drop Import and Advanced Import jobs have access to the Transfer Status window, which provides detailed information about the transfer:
Drag & Drop¶
Drag & Drop Import currently supports the following file types:
- CSV
- ORC
- Parquet
- Shapefile (as a .zip file)
Drag & Drop Import is the simplest of the three methods: drag a file from a local directory into the drop area of GAdmin, or click Choose file to manually select a local file.
If the file's name matches an existing table's name (and matches the table's schema), the records will appended to the existing table; if the file's name does not match an existing table's name, a new table named after the file will be created and the records will be inserted into it. Geometry columns will be automatically inferred based on the source data. No additional customization is available.
Use the Skip Errors check box to have Kinetica skip errors during import and attempt to finish.
Once the table upload is complete, click View Table to view the imported records:

Advanced Import¶
Advanced Import currently supports importing from the following sources:
- AWS S3
- CSV
- Parquet
- Parquet Dataset
- Kinetica tables
- Local Storage (files stored on Kinetica's head node)
- CSV
- ORC
- Parquet
- Shapefile
- Oracle
- PostgreSQL
- SQL Server
- Sybase IQ
- Teradata
The Advanced Import is the GAdmin version of the Kinetica Input/Output (KIO) Tool. Advanced Import provides the ability to import data from a source to this instance of Kinetica using KIO and Spark. For information on how to interact with KIO from the command line, see KIO. For more on how to export data, see Export.
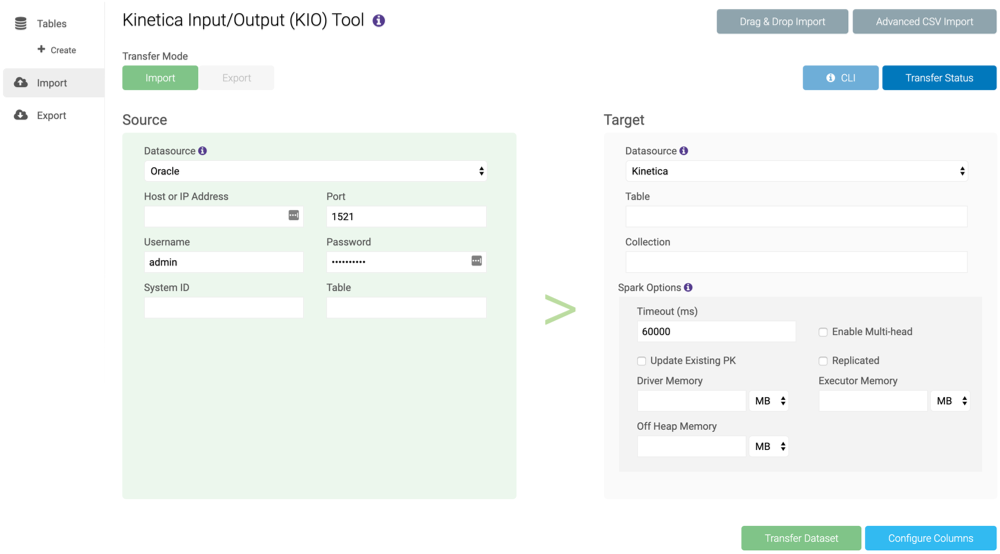
To import data, ensure the Import mode is selected. For the Source section, select a source and fill the required fields. For the Target section, type a name for the table, optionally provide a collection name and update the Spark options, then click Transfer Dataset. If the table exists, the data will be appended to the table; if the table does not exist, it will be created and the data will be inserted into it. The Transfer Status window will automatically open to inform you of the status of the transfer.
Configure Columns¶
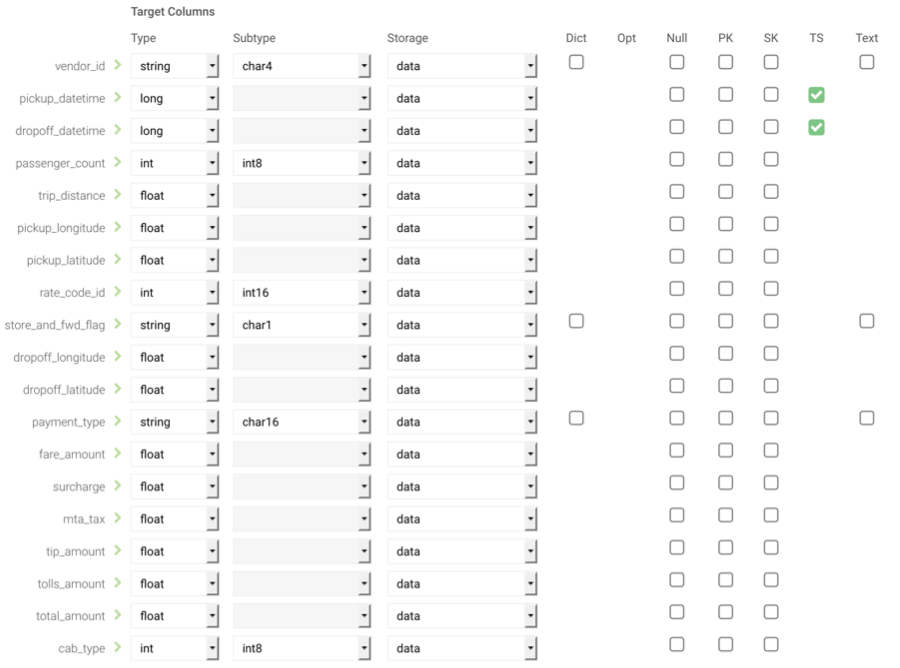
Once all required fields have been filled, columns from incoming data can be configured before importing into Kinetica. Click Configure Columns to enable column configuration. Kinetica will supply its inferred column configurations, but the type, subtype, storage type, and properties are all user-customizable. See Types for more details on column types, subtypes, storage, and properties.
Advanced CSV Import¶
Advanced CSV Import allows you to customize the way a CSV file is
imported. First upload a file using the Select File button, type the
delimiter (,, |, etc.), quote character (", ', etc.),
escape character (\, ", etc.), null string value (\N, etc.), and
whether Kinetica should skip over rows with parsing errors, then choose
whether to import the data into a new table or one that already exists.
Note
If importing data into a table that exists, your CSV file must not contain column names and/or properties in its first row but the column order must match the column order in the table.

If you want to create a new table, you must at least specify the table name, but you can optionally specify a collection name, a type label (if specifying a type header using the first row of the CSV file as described in Export Data), a foreign key, a foreign shard key, an existing type label (if not creating a new type), and replication.

If you want to import data into a table that already exists, you just need to specify the table name and whether to clear any rows that already exist.

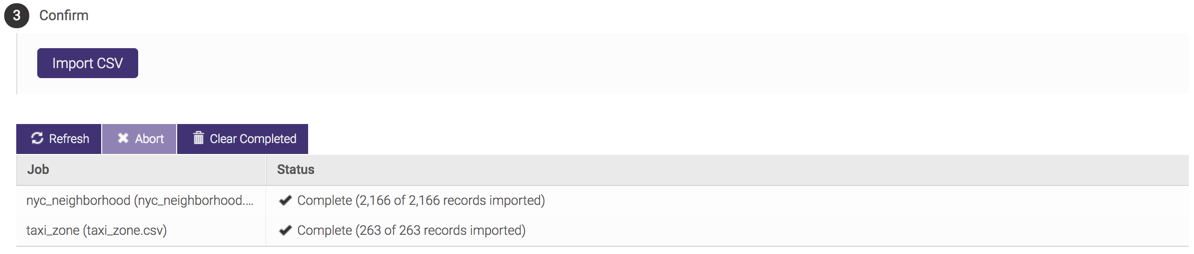
When ready, click Import CSV and the system will provide feedback as it is importing the data.
Export¶
Export provides the ability to export data from this instance of Kinetica to a target. The following targets are currently supported for exporting:
- AWS S3
- CSV
- Kinetica tables
- Local Storage (files stored on Kinetica's head node)
- CSV
- Parquet
- PostgreSQL
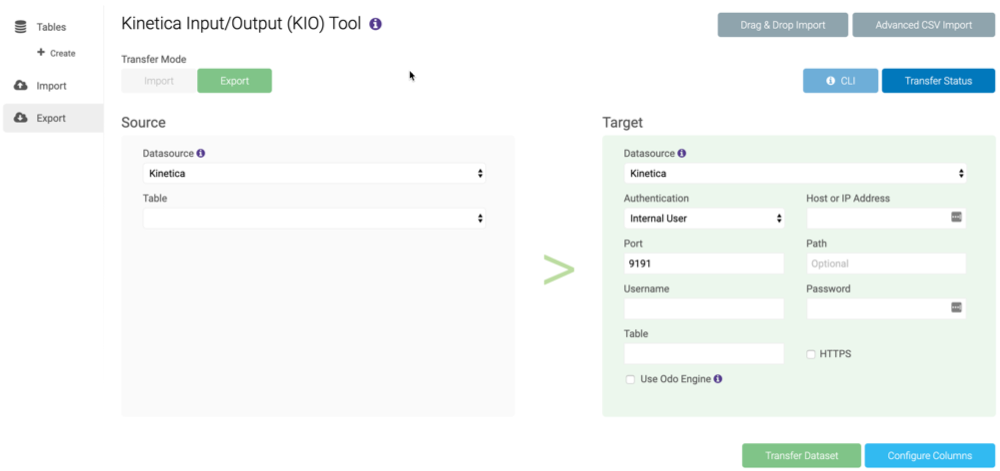
To export data, ensure the Export mode is selected. For the Source section, select a table in Kinetica. For the Target section, select a target and fill the required fields, then click Transfer Dataset. The Transfer Status window will automatically open to inform you of the status of the transfer.
Configure Columns¶
If exporting to another table in Kinetica, columns from the table being exported can be configured once all required fields have been filled. Click Configure Columns to enable column configuration. Kinetica will supply the columns' current configurations, but the type, subtype, storage type, and properties are all user-customizable. See Types for more details on column types, subtypes, storage, and properties.
Kinetica File System (KiFS) Browser¶
The Kinetica File System (KiFS) Browser is a way to browse and manage the
filesystem that's packaged with Kinetica. KiFS must be enabled via the
gpudb.conf file and is only accessible to the gpudb_proc user.
Once KiFS is enabled, the filesystem can be browsed from the
KiFS Browser. Folders can be created in the KiFS mount from here
using the Create Folder button; folders will be created at the level
below Home (see Limitations and Cautions for more information). Files can also be
directly uploaded to the KiFS mount from the KiFS Browser using
the Upload File(s). The file(s) will be uploaded to the currently
selected folder. Once a file is available via the browser, click the file name
to download it.
If a file in the browser is in a format compatible with KIO, an import link will be available in the KIO column. Click the Import link to go to the KIO Tool interface in GAdmin with some information automatically input. See Advanced Import for more information.
KiFS is particularly useful for UDF machine learning model distribution, removing the need to manually distribute the model to each node in a cluster. To read more about interacting with KiFS via command line, review Kinetica File System (KiFS).