Match Graph - Markov Chain (Seattle)¶
The following is a complete example, using the Python API, of matching GPS sample data to road network data via the /match/graph endpoint. For more information on Network Graphs & Solvers, see Network Graphs & Solvers Concepts.
Prerequisites¶
The prerequisites for running the match graph example are listed below:
- Kinetica (v.
7.0.2or later) - Graph server enabled
- Python API
Match graph script- Two CSV files:
Python API Installation¶
The native Kinetica Python API is accessible through the following means:
- For development on the Kinetica server:
- For development not on the Kinetica server:
Kinetica RPM¶
In default Kinetica installations, the native Python API is located in the
/opt/gpudb/api/python directory. The
/opt/gpudb/bin/gpudb_python wrapper script is provided, which sets the
execution environment appropriately.
Test the installation:
/opt/gpudb/bin/gpudb_python /opt/gpudb/api/python/examples/example.py
Important
When developing on the Kinetica server, use /opt/gpudb/bin/gpudb_python to run Python programs and /opt/gpudb/bin/gpudb_pip to install dependent libraries.
Git¶
In the desired directory, run the following but be sure to replace
<kinetica-version>with the name of the installed Kinetica version, e.g.,v7.0:git clone -b release/<kinetica-version> --single-branch https://github.com/kineticadb/kinetica-api-python.git
Change directory into the newly downloaded repository:
cd kinetica-api-pythonIn the root directory of the unzipped repository, install the Kinetica API:
sudo python setup.py install
Test the installation (Python 2.7 (or greater) is necessary for running the API example):
python examples/example.py
PyPI¶
The Python package manager, pip, is required to install the API from PyPI.
Install the API:
pip install gpudb --upgrade
Test the installation:
python -c "import gpudb;print('Import Successful')"
If Import Successful is displayed, the API has been installed as is ready for use.
Data Files¶
The example script makes reference to two data files in the current directory: the Seattle road network CSV file and the raw GPS samples CSV file. These paths can be updated to point to a valid path on the host where the files will be located, or the script can be run with the data files in the current directory.
CSV1 = "road_weights.csv"
CSV2 = "mm_raw_gps.csv"
Script Detail¶
This example is going to demonstrate matching raw GPS points to a Seattle road network, relying on timestamps to determine the start and end point of the GPS signal.
Constants¶
Several constants are defined at the beginning of the script:
HOST/PORT-- host and port values for the databaseOPTION_NO_ERROR-- reference to a /clear/table option for ease of use and repeatabilityTABLE_SRN-- the name of the table into which the Seattle road network dataset is loadedTABLE_GPS-- the name of the table into which the raw GPS samples dataset is loadedTABLE_SOLUTION1/TABLE_SOLUTION2-- the names of the tables into which the solutions are outputGRAPH_S-- the Seattle road network graph
HOST = "127.0.0.1"
PORT = "9191"
OPTION_NO_ERROR = {"no_error_if_not_exists": "true"}
TABLE_SRN = "seattle_road_network"
TABLE_GPS = "raw_gps_samples"
TABLE_SOLUTION1 = TABLE_SRN + "_match_solved"
TABLE_SOLUTION2 = TABLE_SOLUTION1 + "_w_filter_folding"
GRAPH_S = TABLE_SRN + "_graph"
Graph Creation¶
One graph is used for the match graph example utilized in the script:
seattle_road_network_graph, a graph based on the road_weights dataset
(one of the CSV files mentioned in Prerequisites).
The seattle_road_network_graph graph is created with the following
characteristics:
- It is directed because the roads in the graph have directionality (one-way and two-way roads)
- It has no explicitly defined
nodesbecause the example relies on implicit nodes attached to the defined edges - The
edgesare represented using WKT LINESTRINGs in theWKTLINEcolumn of theseattle_road_networktable (EDGE_WKTLINE). The road segments' directionality is derived from theTwoWaycolumn of theseattle_road_networktable (EDGE_DIRECTION). - The
weightsare represented using the time taken to travel the segment found in thetimecolumn of theseattle_road_networktable (WEIGHTS_VALUESPECIFIED). The weights are matched to the edges using the sameWKTLINEcolumn as edges (WEIGHTS_EDGE_WKTLINE) and the sameTwoWaycolumn as the edge direction (WEIGHTS_EDGE_DIRECTION). - It has no inherent
restrictionsfor any of the nodes or edges in the graph - It will be replaced with this instance of the graph if a graph of the same
name exists (
recreate)
create_s_graph_response = kinetica.create_graph(
graph_name=GRAPH_S,
directed_graph=True,
nodes=[],
edges=[
TABLE_SRN + ".WKTLINE AS EDGE_WKTLINE",
TABLE_SRN + ".TwoWay AS EDGE_DIRECTION"
],
weights=[
TABLE_SRN + ".WKTLINE AS WEIGHTS_EDGE_WKTLINE",
TABLE_SRN + ".TwoWay AS WEIGHTS_EDGE_DIRECTION",
TABLE_SRN + ".time AS WEIGHTS_VALUESPECIFIED"
],
restrictions=[],
options={
"recreate": "true"
}
)
The graph output to WMS:
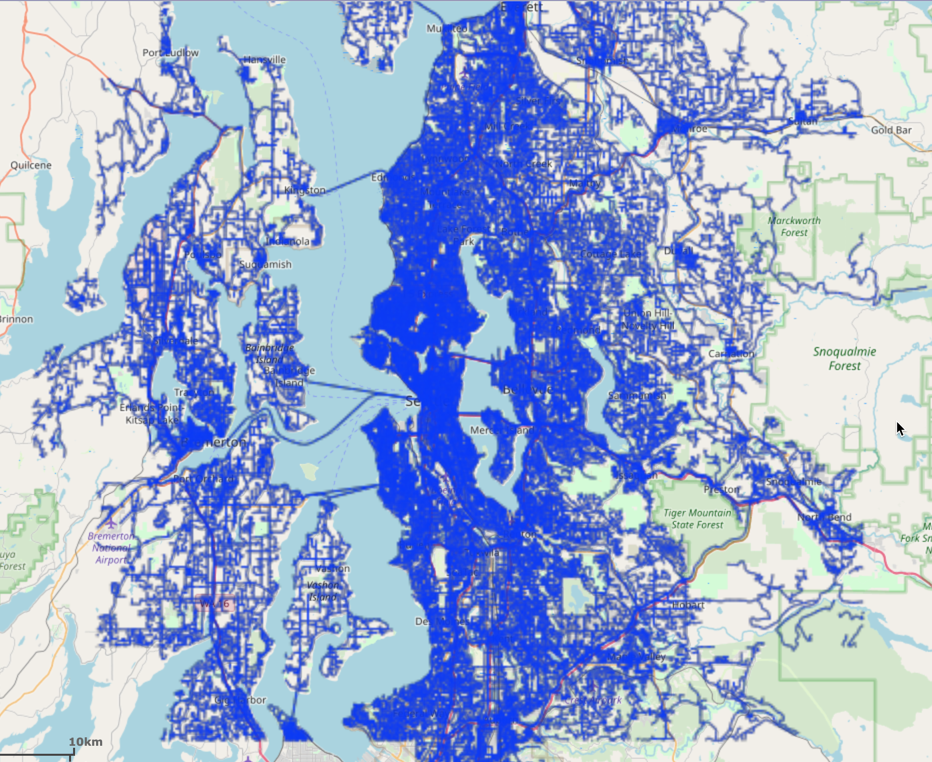
Matching the Graph without Fold-over Filtering¶
Matching to a graph typically requires another table's worth of data. In this
case, the data that will be matched to the graph will come from the
mm_raw_gps dataset (the other CSV file mentioned in Prerequisites). The
sample points are defined using the lon and lat columns as the X and Y
coordinates for each sample point; the datetime column is used for each
sample point's timestamp. The time component is required for determining the
start and end points of the samples.
match_s_graph_response = kinetica.match_graph(
graph_name=GRAPH_S,
sample_points=[
TABLE_GPS + ".lon AS SAMPLE_X",
TABLE_GPS + ".lat AS SAMPLE_Y",
TABLE_GPS + ".datetime AS SAMPLE_TIME"
],
solve_method="markov_chain",
solution_table=TABLE_SOLUTION1,
options={}
)
The mean square error score is returned:
Score for how well the samples matched to the graph (closer to 0 is better): 0.000037145742681
The solution output to WMS:
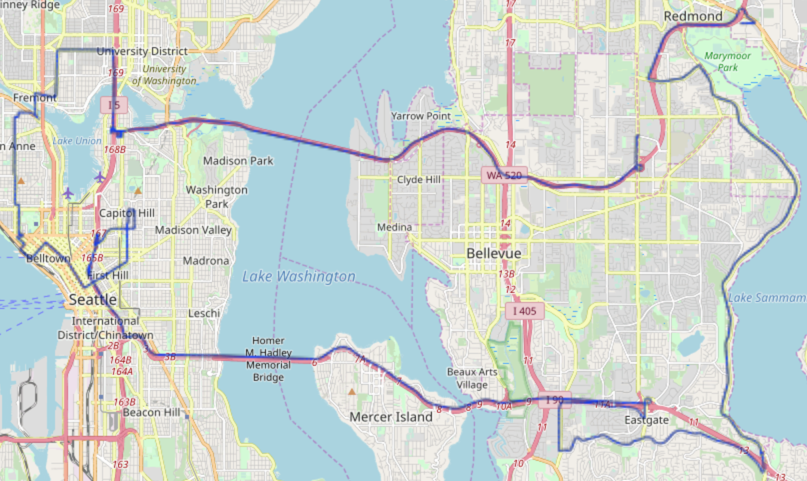
Tip
To demonstrate how successful the map matching solution was, the raw GPS samples can be overlaid on top of the solution using WMS. Below is a sample of the total solution.
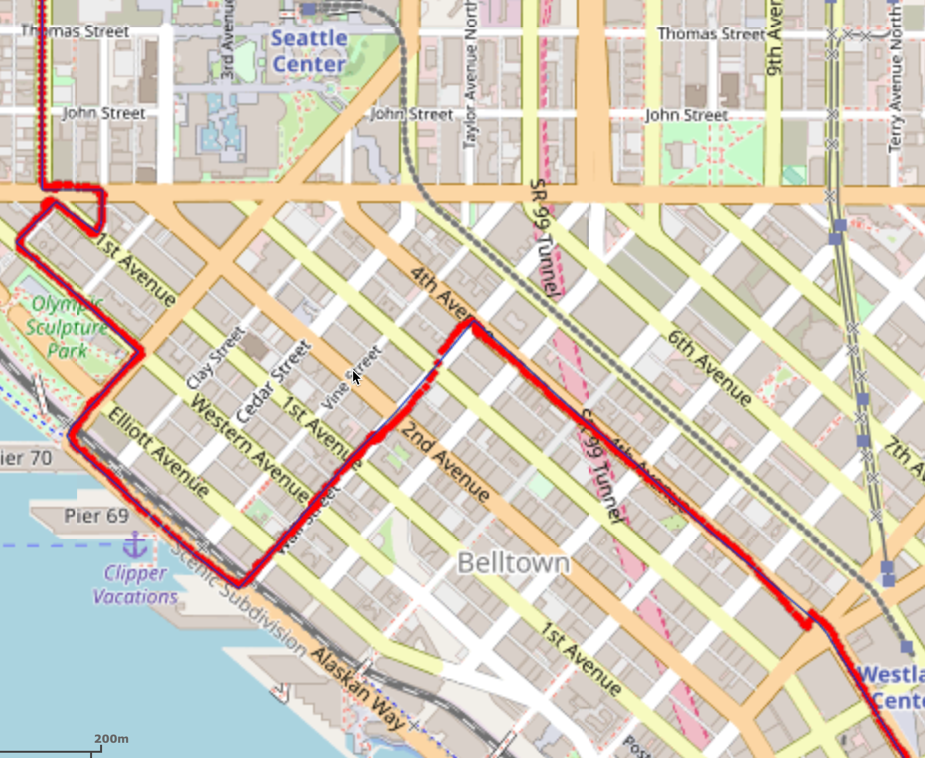
Matching the Graph with Fold-over Filtering¶
To demonstrate how removing fold-over paths from the match solution yields
a different but more accurate score, a similar /match/graph
request to the above can be made but note that removing fold-over paths, e.g.,
setting filter_folding_paths to true, can increase execution time.
match_s_graph_response = kinetica.match_graph(
graph_name=GRAPH_S,
sample_points=[
TABLE_GPS + ".lon AS SAMPLE_X",
TABLE_GPS + ".lat AS SAMPLE_Y",
TABLE_GPS + ".datetime AS SAMPLE_TIME"
],
solve_method="markov_chain",
solution_table=TABLE_SOLUTION2,
options={
"filter_folding_paths": "true"
}
)
The mean square error score is returned:
Score for how well the samples matched to the graph with filter folding (closer to 0 is better): 0.000037339097616
Download & Run¶
Included below is a complete example containing all the above requests, the data files, and output.
To run the complete sample, ensure the match_graph_seattle_markov.py,
road_weights.csv, and mm_raw_gps.csv files are in the same
directory (assuming the locations were not changed in the
match_graph_seattle_markov.py script); then switch to that directory and
do the following:
If on the Kinetica host:
/opt/gpudb/bin/gpudb_python match_graph_seattle_markov.py
If running after using PyPI or GitHub to install the Python API:
python match_graph_seattle_markov.py