Note
This documentation is for a prior release of Kinetica. For the latest documentation, click here.
The Kinetica HA eliminates the single point of failure in a standard Kinetica cluster and provides recovery from failure. It is implemented within the cluster to utilize multiple replicas of data and provides an eventually consistent data store, by default. Through modification of the configuration, immediate consistency can also be achieved, though at a performance cost.
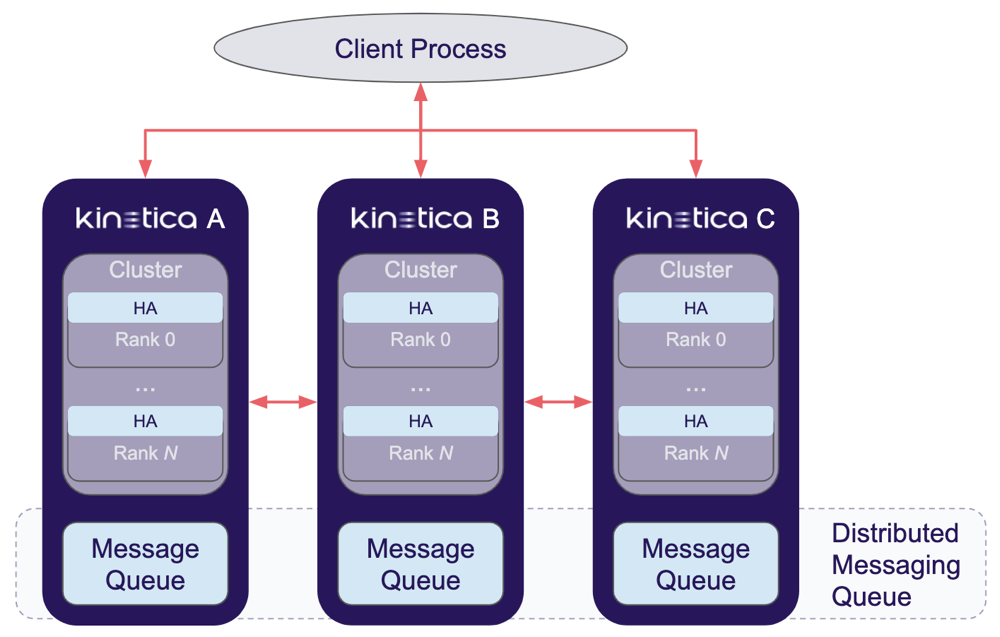
HA Architecture
The Kinetica HA solution consists of four components: an HA-aware client process, high-availability processors within each head node and worker node process in a cluster, two or more Kinetica clusters, and a Distributed Messaging Queue (DMQ). A high-level diagram of the Kinetica HA solution is shown in the High Availability Architecture diagram.
The diagram depicts a three-cluster Kinetica HA ring. Each head node and worker node process in the cluster contains one HA processor (the main HA processing component), thus making HA processing internal to the core database. This reduces the complexity of the HA solution and allows each head node and/or worker node process in the cluster to communicate directly with the DMQ as necessary. By doing this, if a head node or worker node process is down, then the associated cluster can be assumed to be down. This assumption simplifies the request processing and speeds up the HA solution. The diagram also shows that the DMQ contains one message queue per cluster. While the grouping of queues & clusters is a logical one, it can also be a physical one, reusing each cluster's hardware. However, it is recommended that the queues themselves exist on hardware separate from the cluster in order to optimize performance, separating synchronization management from request processing. There may also be more than one message queue per cluster as more instances of message queues are used for redundancy.
Failover Modes
A Kinetica ring itself operates in an active/active state, by default. However, whether it effectively operates in active/active or active/passive modes is governed by its clients:
- Active/Active - clients are configured to connect to any cluster in the HA ring randomly
- Active/Passive - clients are configured to connect to a specific cluster in the HA ring and maintain communications as long as that "active" cluster is up; in the event that the cluster goes offline, clients will fail over to a random "passive" cluster in the HA ring
Failure and Recovery
Head node or worker node process (and by extension, HA processor) failure is possible due to hardware or software failure or the associated cluster being down (either planned or unplanned). Given that all access to the corresponding cluster's services is through that process, all services will be unavailable. During this time, any requests coming from clients will fail, and those clients will redirect their requests to the remaining other clusters.
For non-query operations, the HA processor will also write the request to the DMQ. When any crashed head node or worker node process comes back online and before it starts servicing requests, it will fetch all the queued operations from the DMQ which were stored during its downtime, and replay them in sequence on its corresponding cluster. Query operations are written to DMQ, by default, including those that create result set views, though this behavior can be altered via configuration. For all kinds of operations, once the client process is aware that its current targeted cluster is down, it will fail over to a randomly chosen cluster in its list that is still alive.
An HA processor does not store any data locally and always writes to and reads from the highly-available DMQ. Therefore, there is no need to restore or backup any files on behalf of an HA processor.
High Availability Processing
Kinetica achieves eventual consistency through effective rule-based operation handling.
Operation Handling
A typical interaction with Kinetica begins with a client initiating a request with its corresponding HA-aware client process. The client process sends the request to the primary cluster in its internal list of clusters. The HA processors will then process the request according to its internal request categorization scheme, comprising three operation types:
Synchronous Operations
Operations in this category are determined to be critical to the successful execution of subsequent requests, and in a default installation, include DDL and system/administrative endpoints. They will be relayed to all Kinetica clusters and only succeed if the request is processed successfully by all available clusters. Requests in this category should execute & return quickly, as no further requests will be processed by the receiving cluster for the requesting client until that client's synchronous operation is finished and the necessary information is communicated to the DMQ. Also, requests are passed serially to the other clusters, so a 3-cluster Kinetica system will take 3 times as long to complete each request in this category.
An example synchronous operation request is one to create a table. The table is created in all available clusters, or if an application-level error occurs, the request is rejected back to the client. In this way, the client can be assured that subsequent requests issued to Kinetica, which may be failed over to other clusters, will have that table available. Note that this does not guarantee the presence of the table for other clients issuing requests shortly after the create table request; i.e. the system will not block further requests across all clusters until a given synchronous operation is processed.
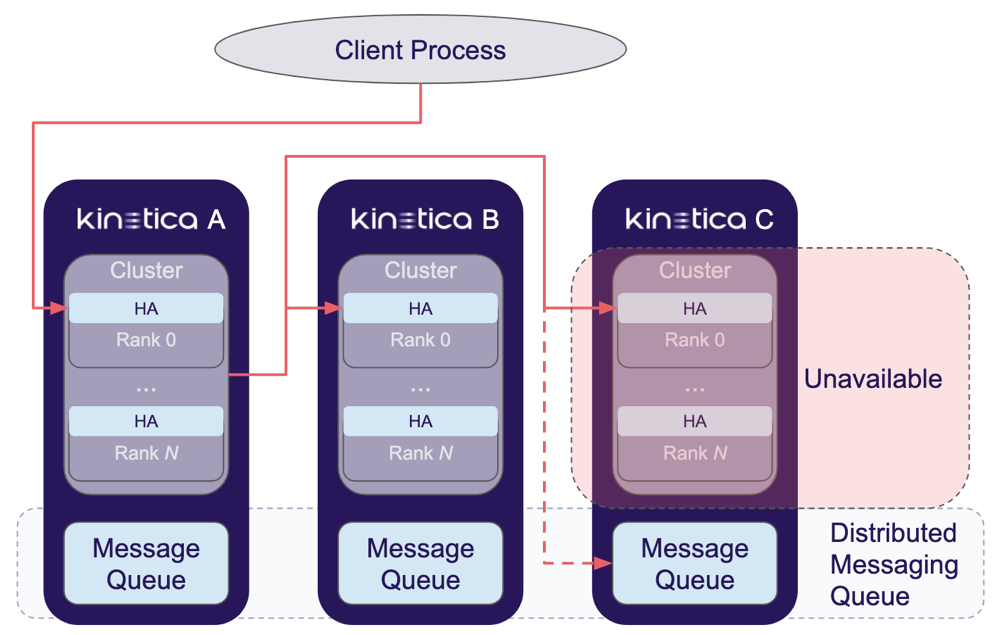
HA Synchronous Operation Flow
Kinetica will handle requests in this category as follows:
- The request is issued to given cluster and a result is received. If an application-level error occurs, the request will be rejected back to the client. If an availability error occurs (connection times out, connection refused, etc...), the request will be rejected back to the client process, which will forward the same request to the next available cluster and restart this service flow.
- If the request is successful on the initial cluster, an HA processor will then issue the same request directly to each of the other available clusters, one after the other. If any operation fails against a cluster, it will be stored in that cluster's message queue for later replay during recovery (the case shown with the downed Kinetica C in the diagram).
- Once the receiving HA processor has received responses from all other clusters, it will return a success response to the client via the client process.
Asynchronous Operations
Operations in this category are determined to be important for data consistency across the Kinetica clusters, but not to the successful execution of subsequent requests. In a default installation, these include DML endpoints. They will be serviced immediately by the receiving cluster and added to the message queues of the remaining clusters and serviced in a timely fashion. Success is determined by the result of the operation on the original cluster only. Because of this asynchronicity, requests in this category can be long-running and will only take as much time as the request takes on a single cluster with some marginal HA-related overhead.
An example asynchronous operation request is one to insert records into a table. The requested records are inserted immediately into the receiving cluster and queued for insert into the remaining clusters, where they will be available shortly afterwards.
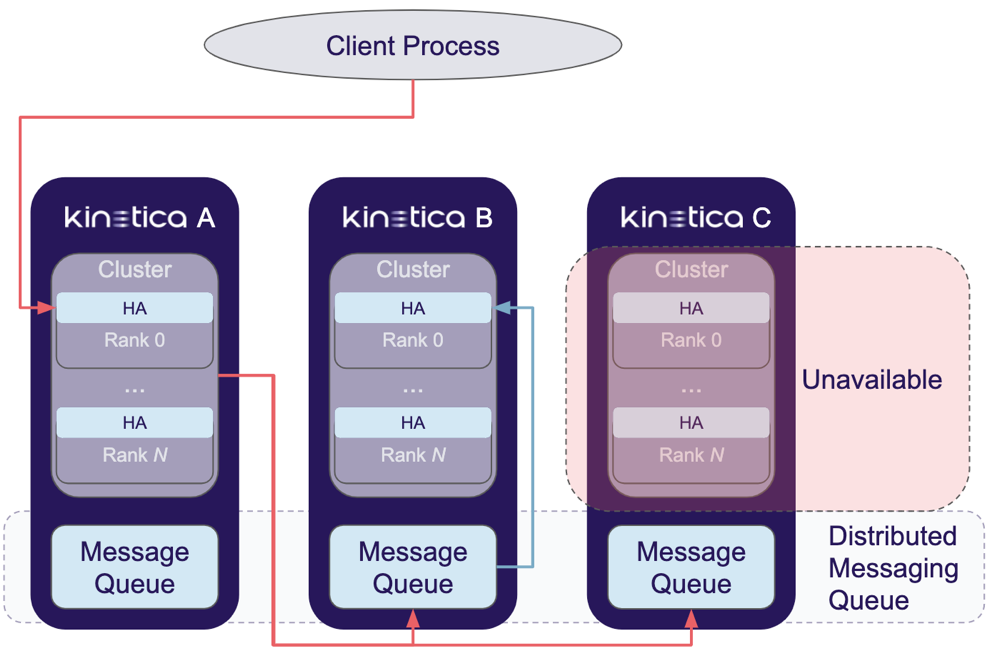
HA Asynchronous Operation Flow
Kinetica will handle requests in this category as follows:
- The request is issued to a given cluster and a result is received. If an application-level error occurs, the request will be rejected back to the client. If an availability error occurs (connection times out, connection refused, etc...), the request will be rejected back to the client process, which will forward the same request to the next available cluster and restart this service flow.
- If the request is successful on the initial cluster, an HA processor on the receiving cluster will then publish the request to the message queue associated with each of the other clusters for later processing. Note that requests are published to the message queues regardless of the up or down state of the corresponding clusters, though only alive clusters will pull operations off of the queue (the case shown with the up Kinetica B & downed Kinetica C in the diagram).
- Once the receiving cluster has finished publishing the request, it will return a success response to the client via the client process.
Queries
Operations in this category are determined to be able to run on any single available cluster and not require any synchronization across clusters. In a default installation, these include data retrieval endpoints. They will be serviced immediately by the receiving cluster and return immediately. As they only run on the receiving cluster, success is only determined by the result of the operation on that cluster.
An example query request is one to aggregate records by groups and return the resulting data set. Since all available clusters should be consistent, aside from any pending asynchronous operations, any single cluster should be able to service the request.
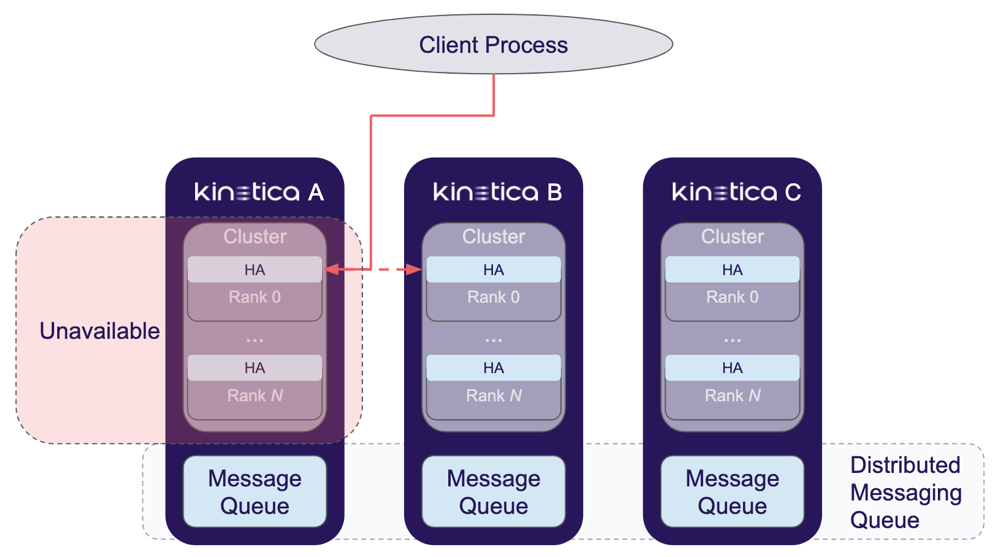
HA Query Operation Flow
Kinetica will handle requests in this category as follows:
- The request is issued to a given cluster and a result is received. If an application-level error occurs, the request will be rejected back to the client. If an availability error occurs (connection times out, connection refused, etc...), the request will be rejected back to the client process, which will forward the same request to the next available cluster and restart this service flow (the case shown with the downed Kinetica A & up Kinetica B in the diagram).
- If the request is successful on the initial cluster, a success response is returned to the client via the client process.
Eventual Consistency
The Kinetica clusters within a given installation will reach eventual consistency through the combined synchronous & asynchronous processing of operations from other clusters during normal conditions and through in-sequence processing of queued operations during recovery.
Data Synchronization
During normal operation, asynchronous operations received & processed by one cluster will be published to the message queue of each of the other clusters. In addition to receiving client requests, the HA processors on the head node and worker node processes also poll the respective cluster's message queue for newly queued asynchronous operations and processes them. In the default configuration, insert requests are pulled off of the queue and executed in multi-threaded fashion. Updates & deletes, on the other hand, will block until all in-flight insert requests have finished and then be processed afterwards. This ordering mechanism only applies to requests pulled off the message queue, and has no bearing on the handling of external client requests.
This leads to eventual consistency, as each cluster, either via handling asynchronous operations directly from clients, or indirectly via the message queue, will end up processing all client requests.
Recovery
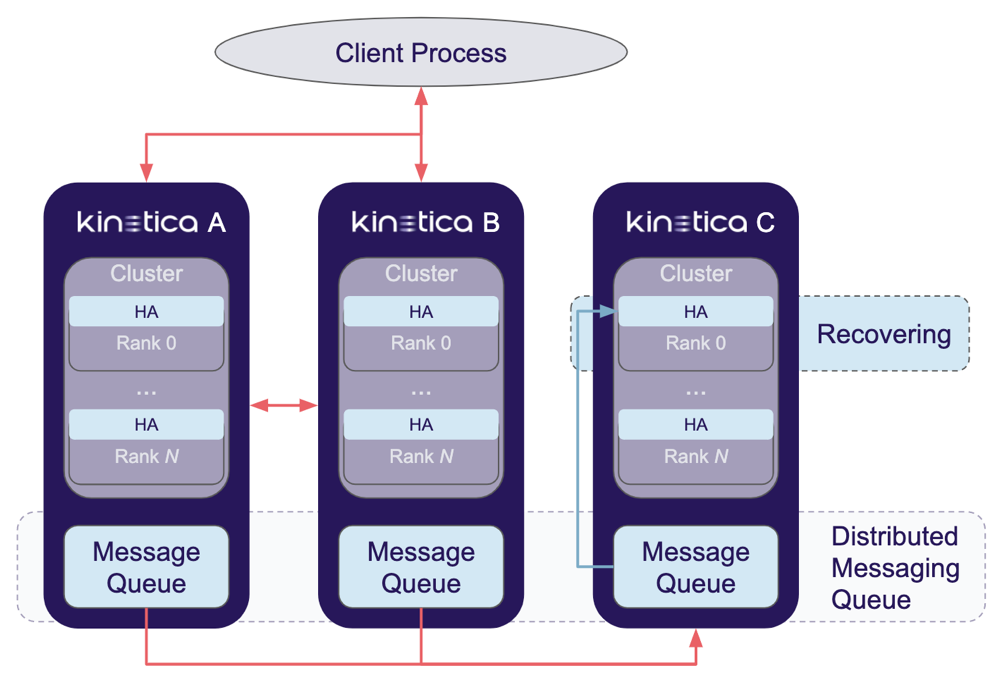
HA Recovery Flow
When a cluster enters into a failed state, inbound client requests will begin to accumulate on its corresponding message queue. When the failure has been corrected and the cluster restarted, the HA processors will begin the recovery synchronization process as follows:
- As the cluster comes up and starts its recovery process, all operations being executed against it by other live clusters will continue to be queued. At this point, the associated cluster is still marked as unavailable and will not yet handle new inbound requests.
- The recovering cluster's HA processors will check its message queue for requests and service those in queued order.
- Once the queue has been drained, the HA processors will be ready for new requests.
In the diagram, Kinetica C is in recovery mode and will be marked as unavailable until it has finished with its queued operations. While it recovers, Kinetica A & Kinetica B will continue to serve requests, adding all operations to its message queue.