Tables
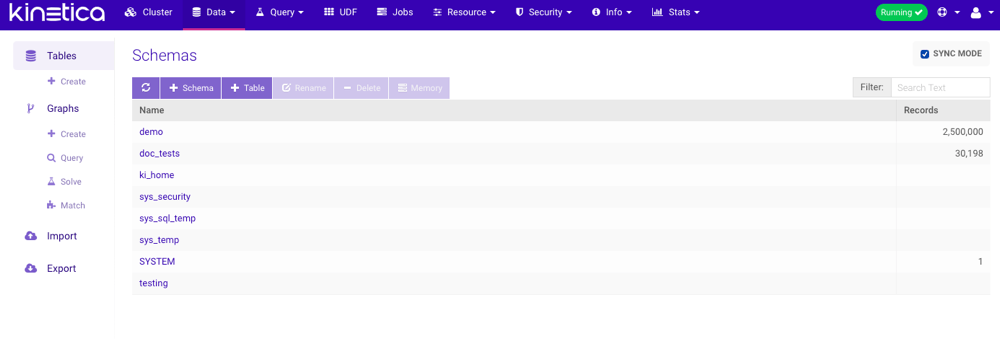
The Tables page provides information about all schemas and contained tables & views in the database in a grid layout.Schema List
The initial grid lists the schemas accessible to the user. Each schema is displayed along with the total number of records across all the tables & views it contains. From this view, the following functionality is available: (Refresh) — refresh the list of schemas
(Refresh) — refresh the list of schemas- + Schema — create a new schema
- + Table — create a new table
- Rename — rename the selected schema
- Delete — delete the selected schema(s)
- Memory — display the current amount of used memory by the tables and views in the selected schema(s)
- Filter — only display schemas matching the given search text and schemas containing tables and/or views matching the given search text
- Sync Mode — if enabled, record counts will be accurate but potentially slower to update
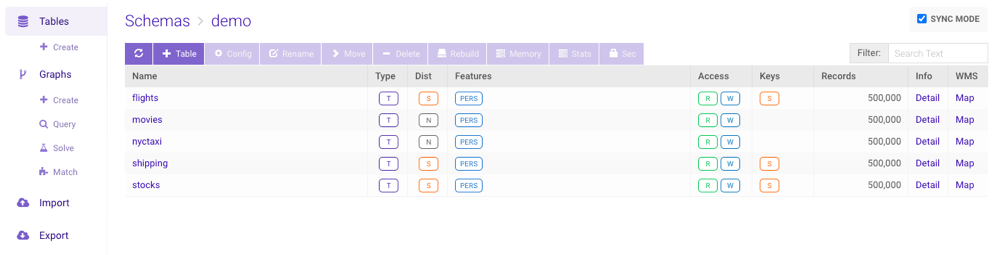
Table/View List
Clicking on a schema will show a grid view of all the tables & views that schema contains, with details about each. Available are the object type, type of distribution (replicated, sharded, or neither), feature set (see list below), global access rights (read/write), keys (primary, shard, and foreign) and associated columns, and the record count. The types of objects are as follows:- T — table
- MV — materialized view
- LV — logical view
- ME — materialized external table
- PERS (PERSISTED) — the table exists on disk & in memory (i.e., not memory-only) and will exist across database restarts
- JOIN — a join view or materialized view that ends in a join view
- RESU (RESULT_TABLE) — results from endpoint operations like Create Projection and Create Union
- VIEW — a filtered view, a join view, or a materialized view that ends in a filtered or join view
- (Refresh) — refresh the list of tables & views
- + Table — create a new table
- Config — modify the selected table
- Rename — rename the selected table
- Move — move the selected table(s) and/or view(s) to a different schema
- Delete — delete the selected table(s) and/or view(s)
- Rebuild — rebuild the selected table(s) and/or view(s)
- Memory — display the current amount of used memory for the selected table(s) and/or view(s)
- Stats — display statistics regarding a selected column or all columns in the selected table or view, e.g., estimated cardinality, mean value, standard deviation, etc.; and recommendations for improving the structure of the table, e.g., dictionary encoding, smaller column type, etc.
- Sec — manage row- and column- security for the selected table or view
- Filter — only display tables and views matching the given search text
- Sync Mode — if enabled, record counts will be accurate but potentially slow
Creating
A table can be created by clicking Create (underneath Tables) on the left menu to navigate to the Create Table page. After configuring the name, containing schema name, distribution scheme, keys, column set, tier strategy definition, and partitioning, click Create New Table.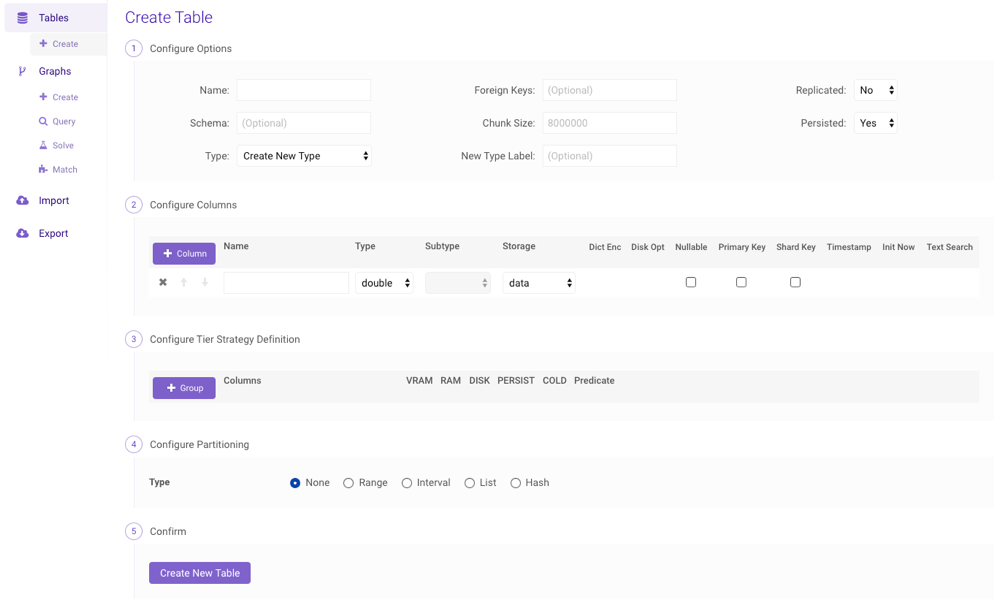
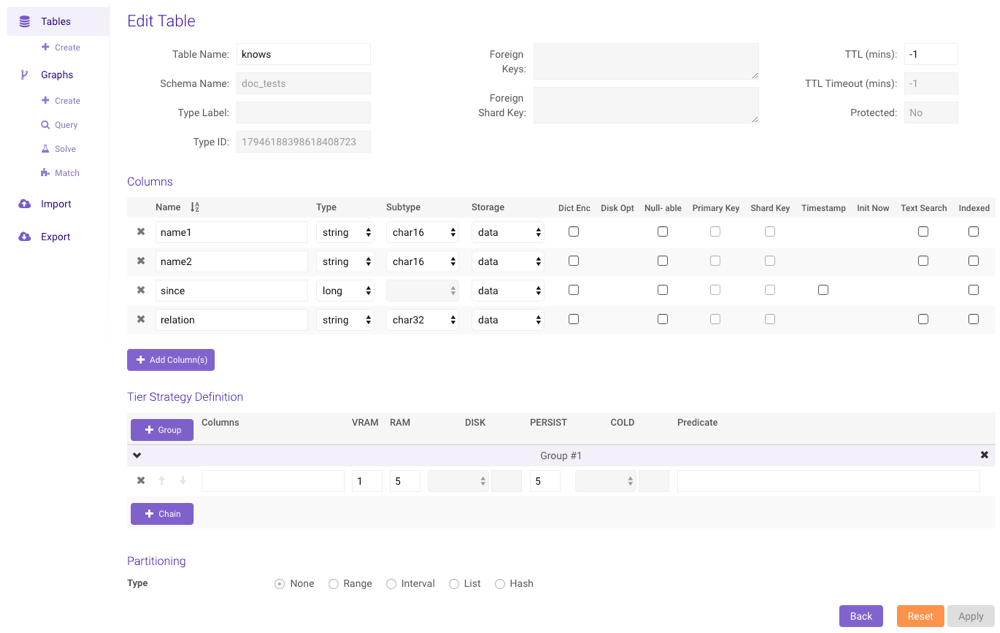
Defining a Tier Strategy
From the Edit Table page:- Click + Group to append additional column strategy groupings to the table
- Click + Chain to append additional priority definitions to a group
- Provide a comma-separated list of columns, an eviction priority for each available tier (tiers are defined in /opt/gpudb/core/etc/gpudb.conf), and an optional predicate
Example
For instance, consider the following tier strategy, applied to a table with a timestamp column namedlast_seen, a positive integer id column, and a
string name column:
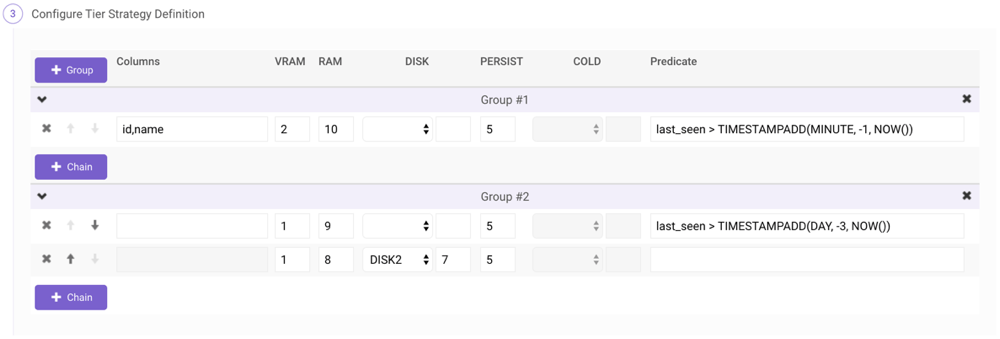
Partitioning
From the Edit Table page:- Select a partition type.
- Provide as many Key(s) as necessary. Click + to add key expressions.
- Provide as many Definition(s) as necessary. Click + to add definitions.
Example
To create a range-partitioned table with the following criteria:- partitioned by the date/time of the order
- partitions for years 2016, 2017, 2018, & 2019
- records not in that range go to the default partition

Configuring
To configure an existing table, click Config, update the table configuration as necessary, and click Apply. Click Reset to discard any pending modifications. Allowed modifications include:- Renaming the table
- Modifying the TTL
- Renaming the non-primary/shard key columns
- Modifying the type, subtype, storage, and properties of a non-primary/shard key column
- Removing any non-primary/shard key columns
- Adding new columns
- Adjusting the tier strategy definition; see Defining a Tier Strategy for assistance.
- Adjusting the table partitioning; note that only existing range or list partitions can be adjusted
Moving
To move one or more tables and/or views to another schema, select the table(s)/view(s) (avoid clicking any table/view name, as that will open the Data Grid page) and then click Move. In the pop-up, select which schema to move them to and click Move.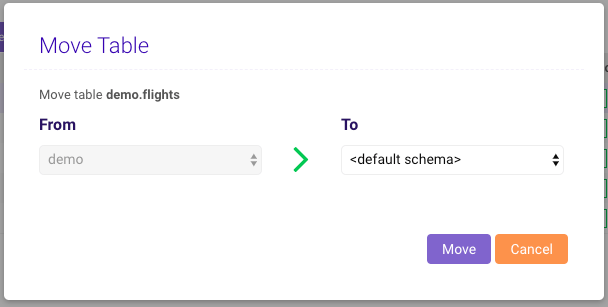
Deleting
To delete one or more tables and/or views, select the table(s)/view(s) (avoid clicking any table/view name, as that will open the Data Grid page) and then click Delete. In the pop-up, confirm the deletion.Rebuilding
To rebuild one or more tables and/or views if you are unable to query them, select the table(s)/view(s) (avoid clicking any table/view name, as that will open the Data Grid page) and then click Rebuild. In the pop-up, confirm the rebuild. Acknowledge the warning, then the selected objects will be rebuilt. For more information on rebuilding the entire database, see Admin.Detailed Table Information
To view table/view detail, structure, memory usage, and tier strategy information, click Detail in the Info column. The column grid can be exported to CSV by clicking Export CSV.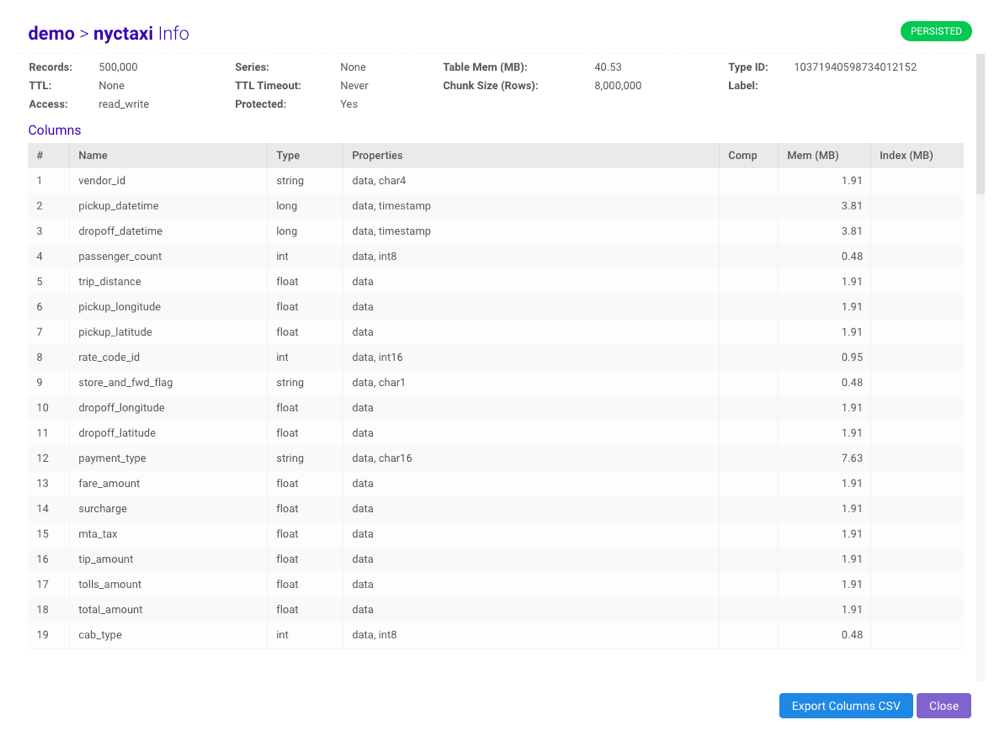
WMS
If your data contains coordinates and/or geometry data, you can:- When viewing the list of tables (Data —> Tables), click the Map link in the WMS column
- When browsing a table’s datagrid, click the WMS button in the top bar
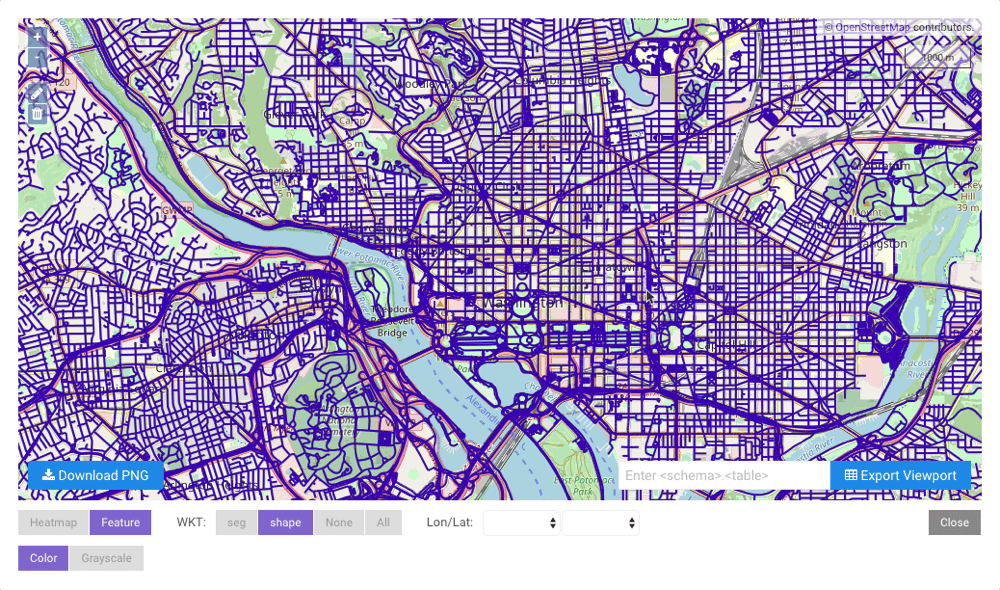
.png file of the current viewport. Provide a table name and click
Export Viewport to export the points in the current viewport to
a separate table; note that if any polygon(s) were drawn on the
map, only the points inside those polygons will be exported to the new table.
The map will default to Heatmap mode. To render full WKT
geometry, click Feature. Whilst rendering features, click a
feature on the map to display additional information about the feature.
doublefloatintint16int8longtimestamp(the raw epoch value will be used to render the point)decimal
wktwkb
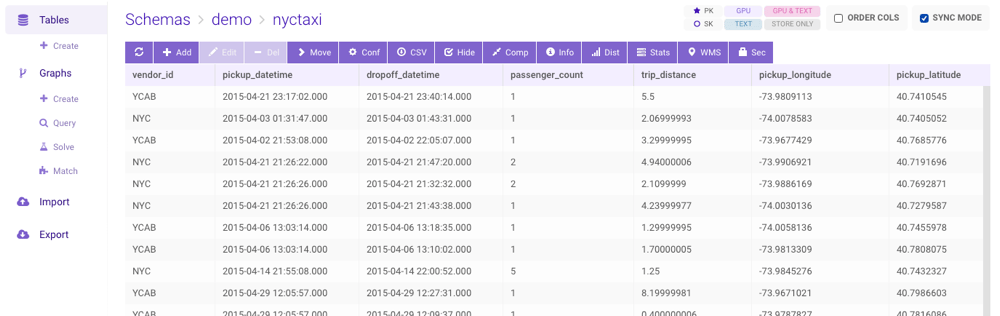
Data Grid
To view the individual records in a table, click the table name. This will display the data grid page. From here, the following functionality is available:- (Refresh) — refresh the table
- Add — insert a new record
- Edit — modify the selected record
- Delete — delete the selected record
- Move — move the table or view to a different schema
- Conf — modify the table or view
- CSV — export data to CSV
- Hide — hide displayed columns within the grid
- Info — display table detail
- Dist — display cross-node data distribution graph
- Stats — display statistics regarding a selected column or all columns in the table, e.g., estimated cardinality, mean value, standard deviation, etc., and recommendations for improving the structure of the table, e.g., dictionary encoding, smaller column type, etc.
- WMS — plot data from tables with geospatial data on a map
- Sec — manage row- and column- security for the table
- Order Cols — If enabled, the columns will be displayed alphabetically
- Sync Mode — if enabled, table row counts will be accurate but potentially slow
Export Data
From the data grid page, select CSV. You will have the option to export all of the data or records within a range, specify the type of header, and how to order the data on export.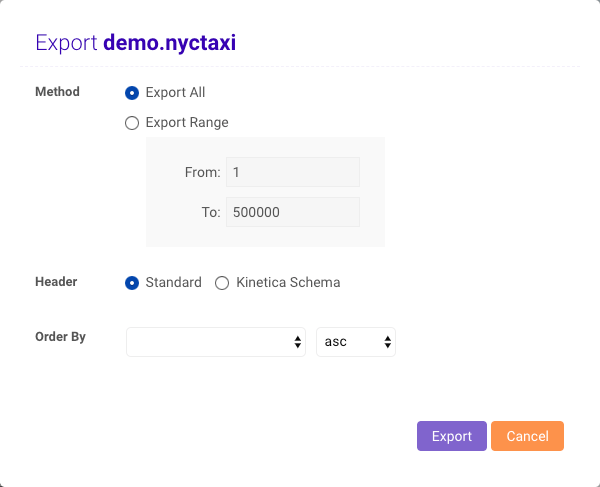
<schema>.<table>.csv. The standard header is just a comma-delimited list of
column header names:


Null values are represented as
\N. This can be changed by
modifying the data_file_string_null_value parameter in
/opt/gpudb/tomcat/webapps/gadmin/WEB-INF/classes/gaia.properties.Advanced Table Security
Advanced table security (e.g., row- and column-level) can be enabled on a per-table basis for select users and roles by:- When viewing the list of tables (Data —> Tables), select a table then click the Sec button in the top bar
- When browsing a table’s datagrid, click the Sec button in the top bar
table_read permission on a selected table for
the row- and/or column-level security to apply. Review
Row-Level Security and Column-Level Security for
more information.
Advanced Table Security can only be accessed by users with the
system_admin permission.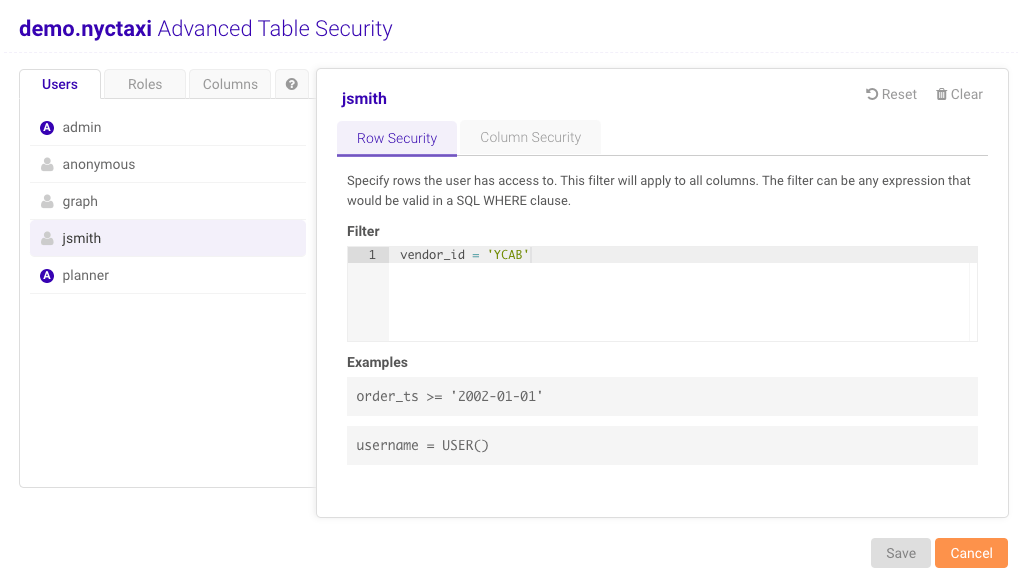
Users
Individual users can have row- and column-level security imposed on them, restricting or granting access to particular data. To apply security to a user:- Navigate to the Advanced Table Security window and display the Users tab.
-
Select a user from the list.
Row- and column-level security cannot be configured for users with the
system_adminpermission. -
Apply Row Security and Column Security as necessary.
-
To apply Row Security:
-
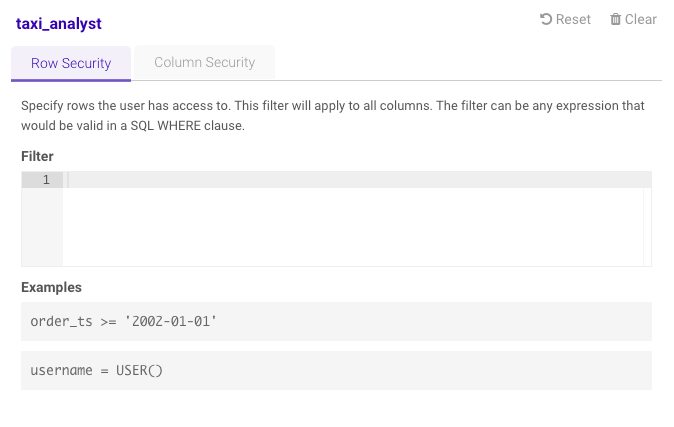
Click the Row Security tab.
-
Provide a valid SQL
WHERE-like expression in the Filter text field to specify entire rows the user has access to that meet the given filter condition.
-
Click the Row Security tab.
-
To apply Column Security:
-
Click the Column Security tab.
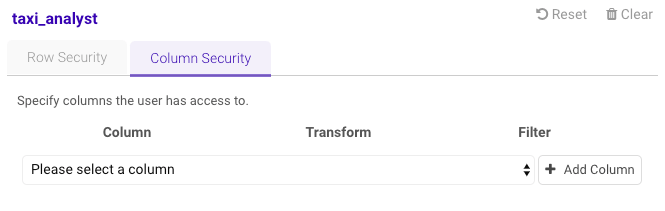
- Select a column from the drop-down menu.
- Click Add Column.
-
Optionally, if the column is a
stringcolumn, select a Transform option:-
Mask — the column value will be masked after some length,
for some width of characters, with a select character. If no mask
exists for the column currently, one must be defined. Click
 to
jump to the Columns table and define one. See
Columns for more information.
to
jump to the Columns table and define one. See
Columns for more information.
- Obfuscate — each unique original column value will be exchanged for a unique non-negative number
Review Column-Level Security for more information on masking and obfuscation. -
Mask — the column value will be masked after some length,
for some width of characters, with a select character. If no mask
exists for the column currently, one must be defined. Click
-
Optionally, apply a valid SQL
WHERE-like expression in the Filter text field. - Repeat the previous steps for as many columns as necessary.
-
Click the Column Security tab.
-
To apply Row Security:
- Click Save and confirm the update for the selected user.
Roles
Individual roles can have row- and column-level security imposed on them, restricting or granting access to particular data. To apply security to a role:- Navigate to the Advanced Table Security window and display the Roles tab.
-
Select a role from the list.
Row- and column-level security cannot be configured for roles with the
system_adminpermission. -
Apply Row Security and Column Security as necessary.
-
To apply Row Security:
-
Click the Row Security tab.
-
Provide a valid SQL
WHERE-like expression in the Filter text field to specify entire rows the user has access to that meet the given filter condition.
-
Click the Row Security tab.
-
To apply Column Security:
-
Click the Column Security tab.
- Select a column from the drop-down menu.
- Click Add Column.
-
Optionally, if the column is a
stringcolumn, select a Transform option:-
Mask — the column value will be masked after some length,
for some width of characters, with a select character. If no mask
exists for the column currently, one must be defined. Click to
jump to the Columns table and define one. See
Columns for more information.
- Obfuscate — each unique original column value will be exchanged for a unique non-negative number
Review Column-Level Security for more information on masking and obfuscation. -
Mask — the column value will be masked after some length,
for some width of characters, with a select character. If no mask
exists for the column currently, one must be defined. Click
-
Optionally, apply a valid SQL
WHERE-like expression in the Filter text field. - Repeat the previous steps for as many columns as necessary.
-
Click the Column Security tab.
-
To apply Row Security:
- Click Save and confirm the update for the selected role.
Columns
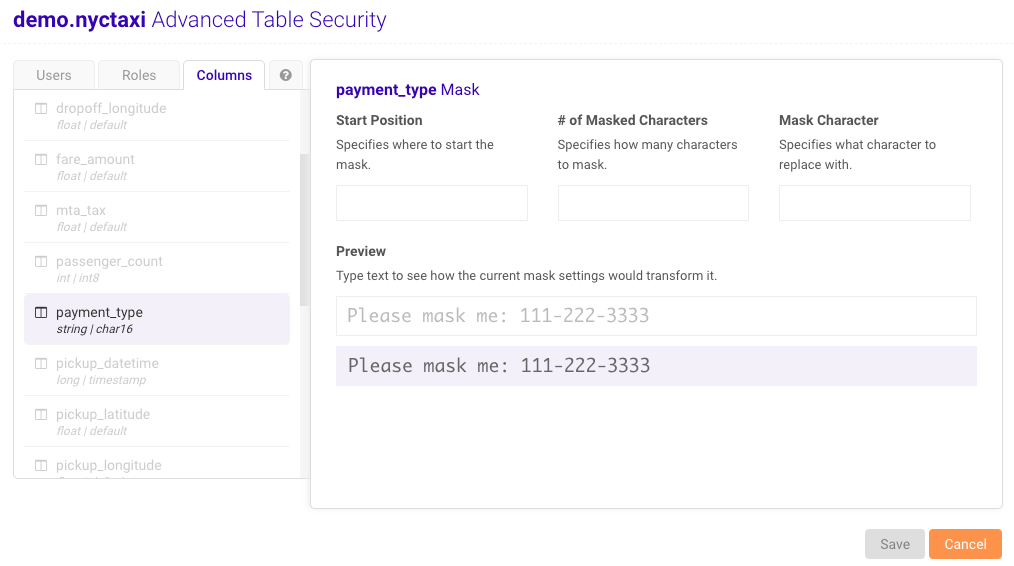
Anystring columns in the selected table can have pre-configured masks
applied when setting column-level security for a user or role. To create a mask
for a column:
- Navigate to the Advanced Table Security window and display the Columns tab.
- Select a valid column from the list.
- Specify a Start Position for the mask.
- Specify the # of Masked Characters.
- Specify the Mask Character.
- Optionally, type into the Preview field to preview the mask before saving.
- Click Save and confirm the column mask.
Example
Userjsmith is a human resources liaison for the engineering department
with access to employee information. The security for the employees table
that contains said information is configured in such a way that user jsmith:
- Can see full information for their own username
- Can only see the last 4 of an SSN and an obfuscated salary for employees outside of their assigned department
-
From the
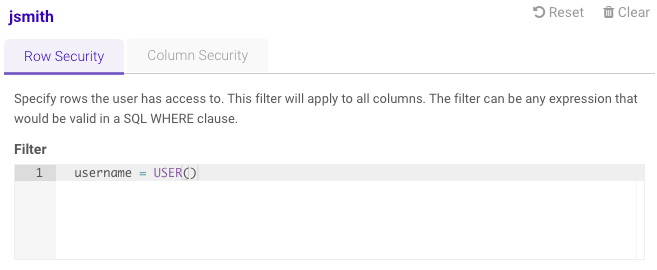
employeestable, click Sec along the top, and then selectjsmithfrom the Users list. -
On the right side of the window, under Row Security, input the
filter for the engineering department:
-
Click Column Security and input the obfuscated
salarycolumn & the maskedssncolumn: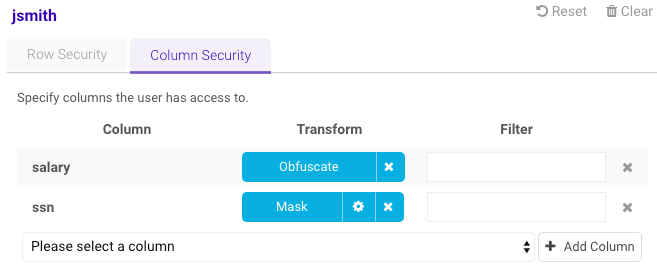
-
Click the icon next to Mask to configure the masking
values:
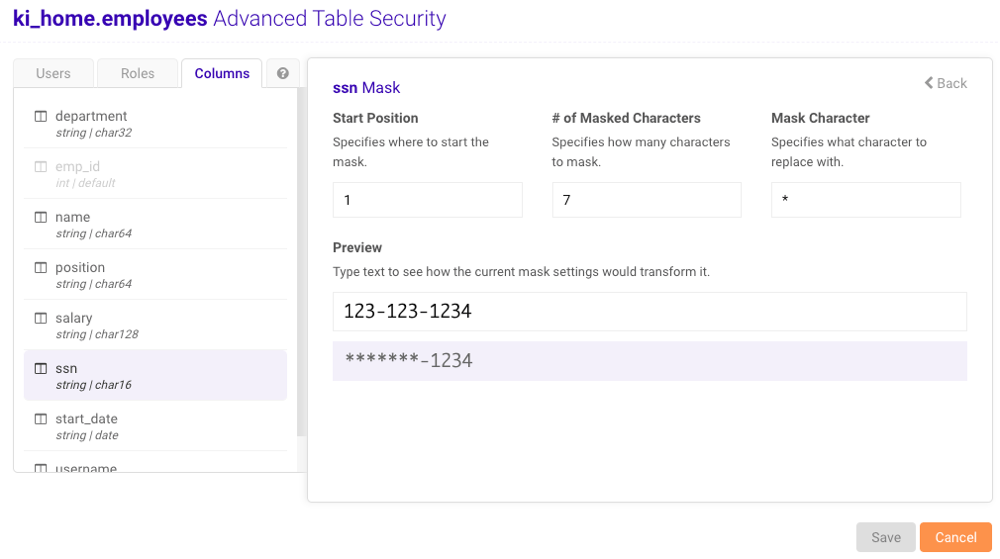
- Click Save.
Graphs
The Graphs section provides the ability to manage and execute operations against graphs. The following sections are available under Graphs:- Create — create a new graph
- Query — run a query against an existing graph
- Solve — run a solver algorithm against an existing graph
- Match — run a matching algorithm against an existing graph
On any of the interfaces described below, click History to
view previous requests made to that particular interface, view details
about each request, reload a request, or view WMS for the request (if
Enable Graph Draw was set to 
True)
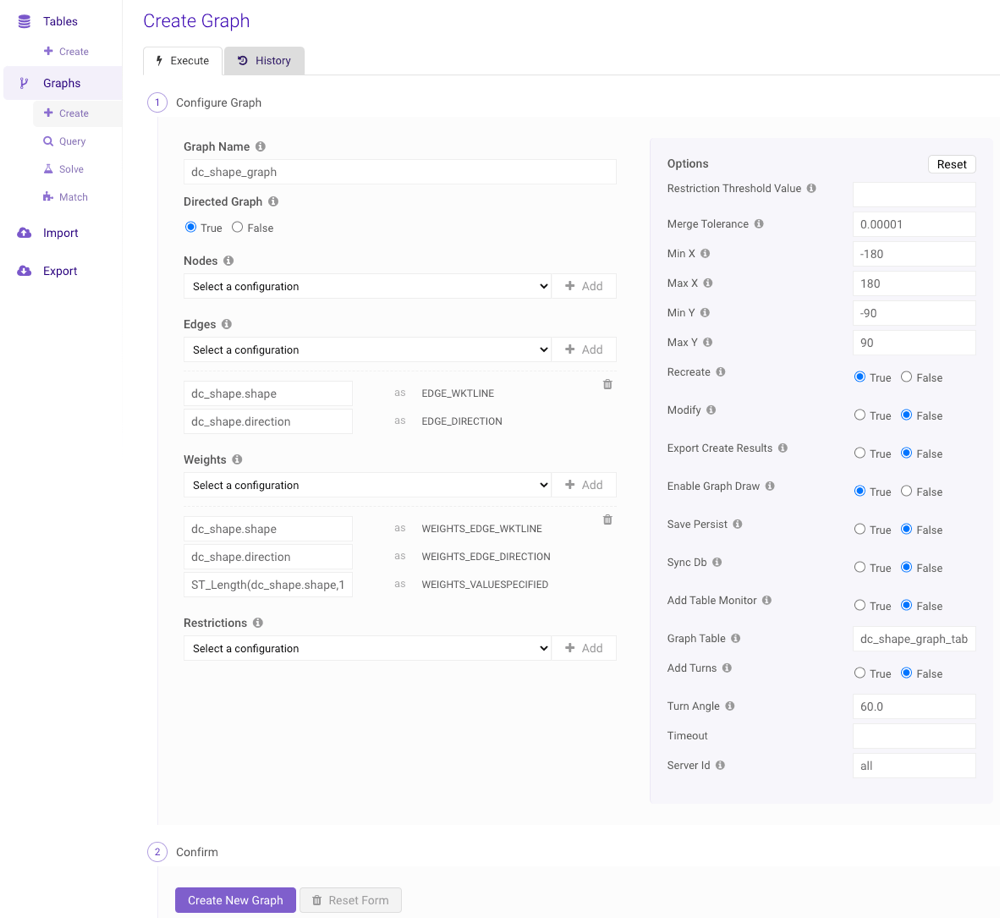
Create
A graph can be created by clicking Create (underneath Graphs) on the left menu to navigate to the Create Graph page. Follow the steps below to create a graph using the interface:It’s highly recommended you consult
Graphs & Solvers Concepts and
/create/graph for information on identifiers,
valid configurations, combinations, and graph options before
creating a graph with GAdmin. If multiple graph servers are
available, it’s also recommended you consult the
Distributed Graph Servers documentation.
- Provide a name for the graph.
- Choose whether the graph should be directed
- Optionally, select a desired node configuration from the Nodes drop-down menu and click Add +. For each identifier that appears after adding the configuration to the graph, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Select a desired edge configuration from the Edges drop-down menu and click Add +. For each identifier that appears after adding the configuration to the graph, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Select a desired weight configuration from the Weights drop-down menu and click Add +. For each identifier that appears after adding the configuration to the graph, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Optionally, select a desired restriction configuration from the Restrictions drop-down menu and click Add +. For each identifier that appears after adding the configuration to the graph, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Adjust the options as desired.
- Click Create New Graph.
Query
An existing graph can be queried by clicking Query (underneath Graphs) on the left menu to navigate to the Query Graph page. Follow the steps below to query a graph using the interface:It’s highly recommended you consult
Querying a Graph and /query/graph
for information on query identifiers, valid query configurations,
query combinations, and query graph options before querying a
graph with GAdmin. If multiple graph servers are
available, it’s also recommended you consult the
Distributed Graph Servers documentation.
- Select an existing graph from the Graph Name drop-down menu.
-
Select a desired query configuration from the
Queries drop-down menu and click Add +. For each
query identifier that appears after adding the
configuration, provide a column name, expression, or raw value (as outlined
in Components and Identifiers) to use with the query identifier. Repeat as necessary.
If you select
QUERY_NODE_WKTPOINT, you can click to
open the graph in the WMS viewer and manually select point(s) on the
map.
to
open the graph in the WMS viewer and manually select point(s) on the
map.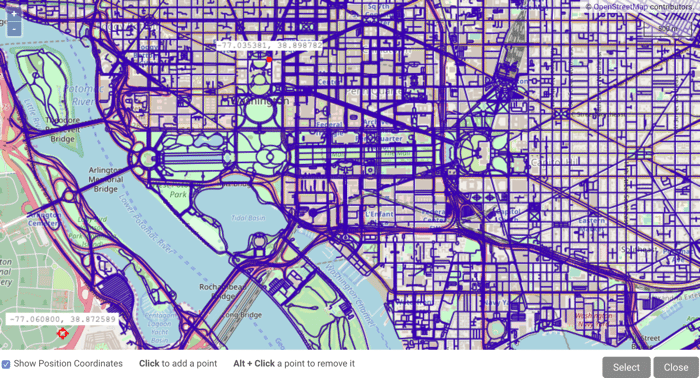
- Optionally, select a desired restriction configuration from the Restrictions drop-down menu and click Add +. For each identifier that appears after adding the configuration, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Provide an adjacency table name into which the results will be output.
- Provide the number of rings (or hops) for the query.
- Adjust the options as desired.
- Click Query Graph.
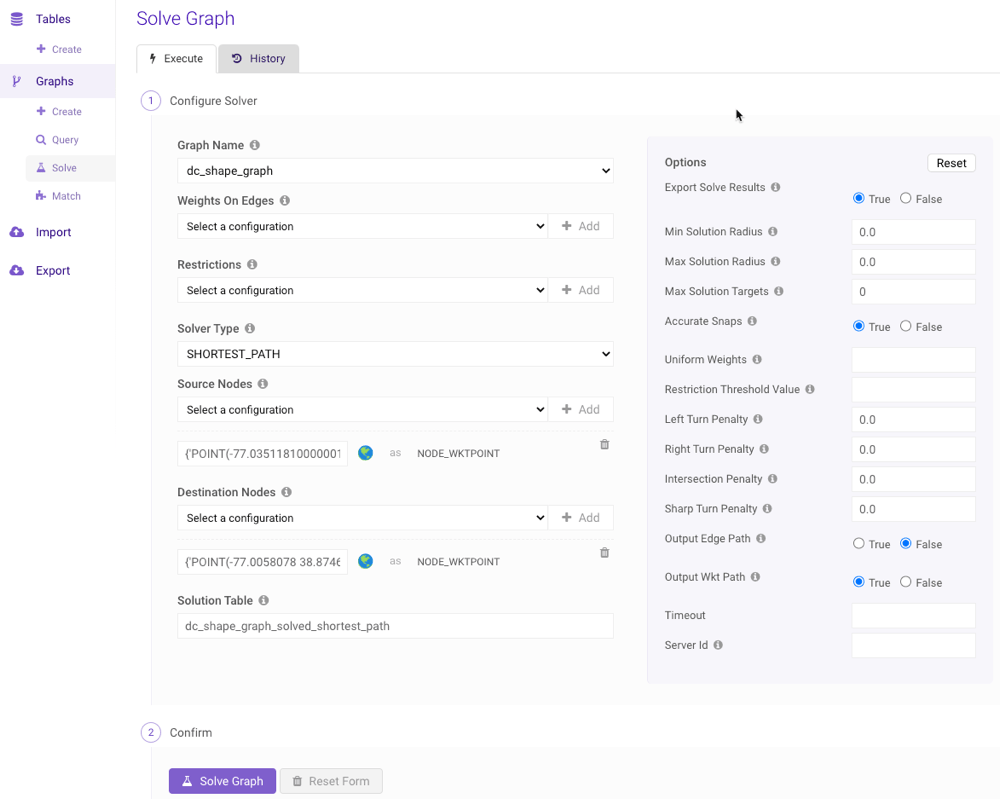
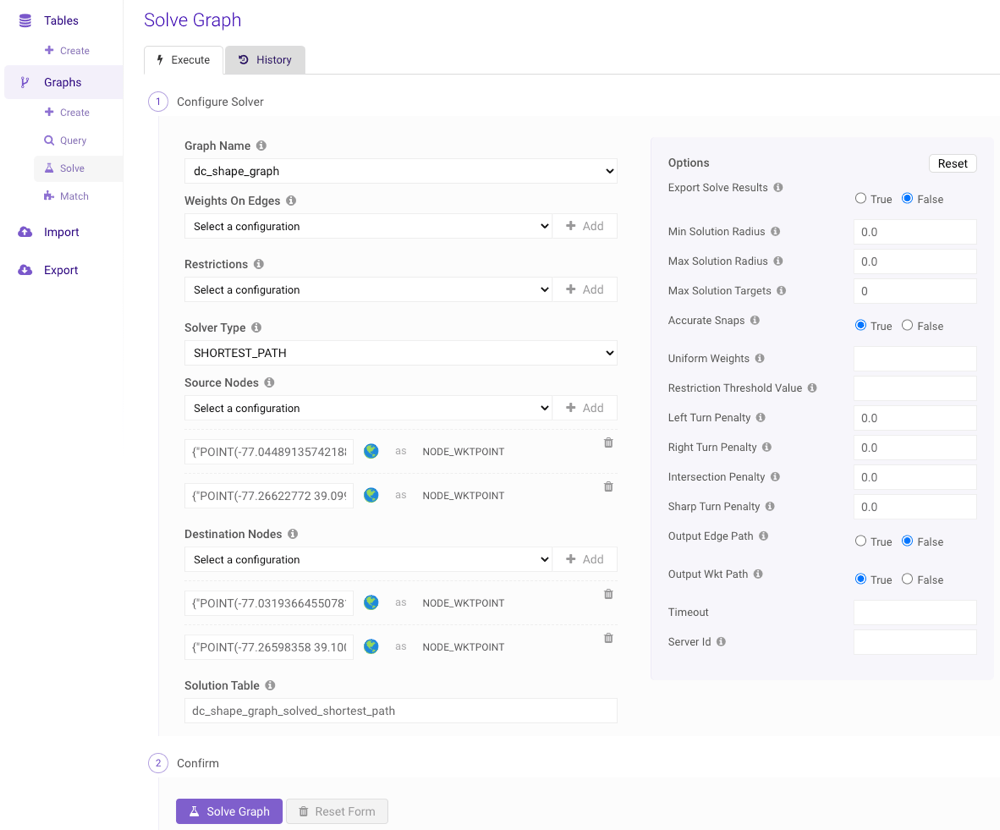
Solve
An existing graph can be solved using a variety of methods by clicking Solve (underneath Graphs) on the left menu to navigate to the Solve Graph page. Follow the steps below to solve a graph using the interface:It’s highly recommended you consult
Graphs & Solvers Concepts,
/solve/graph, and the
Solve Graph examples for
information on identifiers, valid configurations, combinations,
and options before solving a graph with GAdmin. If multiple
graph servers are available, it’s also recommended you consult the
Distributed Graph Servers documentation.
- Select an existing graph from the Graph Name drop-down menu.
- Optionally, select a desired weight configuration from the Weights on Edges drop-down menu and click Add +. For each identifier that appears after adding the configuration, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Optionally, select a desired restriction configuration from the Restrictions drop-down menu and click Add +. For each identifier that appears after adding the configuration, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Select a solver from the Solver Type drop-down menu.
-
Select a node type from the Source Nodes drop-down menu and click
Add +. For each field that appears after adding the node type,
provide a column name, expression, or raw value (as outlined in
Components and Identifiers) to use with the identifier. Repeat as necessary. If
adding multiple source nodes, they should all be of the same type.
If you select
NODE_WKTPOINT, you can click to open
the graph in the WMS viewer and manually select point(s) on the map. -
Select a node type from the Destination Nodes drop-down menu and
click Add +. For each field that appears after adding the node
type, provide a column name, expression, or raw value (as outlined in
Components and Identifiers) to use with the identifier. Repeat as necessary. If
adding multiple source nodes, they should all be of the same type.
If you select
NODE_WKTPOINT, you can click to open
the graph in the WMS viewer and manually select point(s) on the map.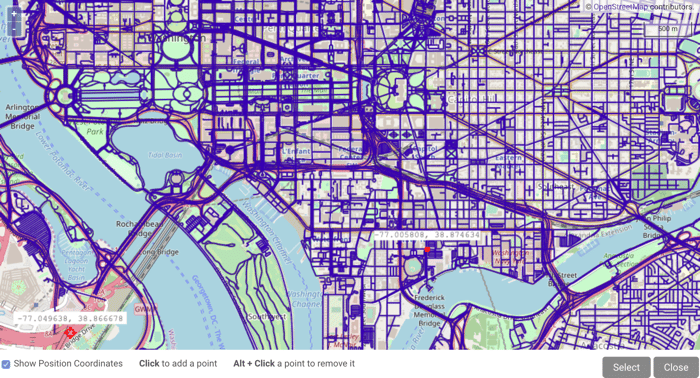
- Provide a solution table name into which the results will be output.
- Adjust the options as desired.
-
Click Solve Graph. A WMS request of the solution(s) will open.
Click a solution route to see the start (
 ) and end (
) and end ( ) points:
) points:
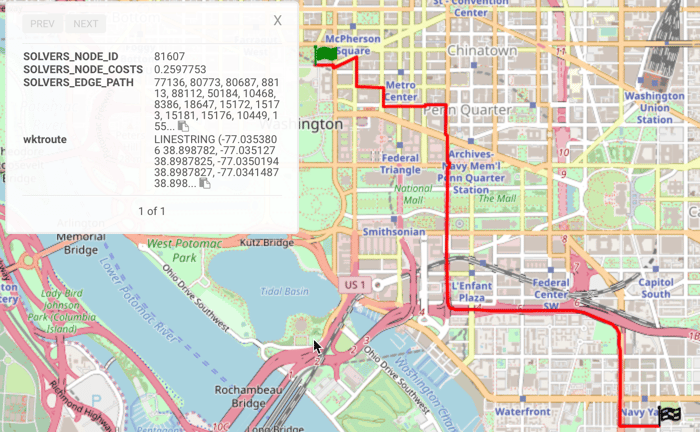
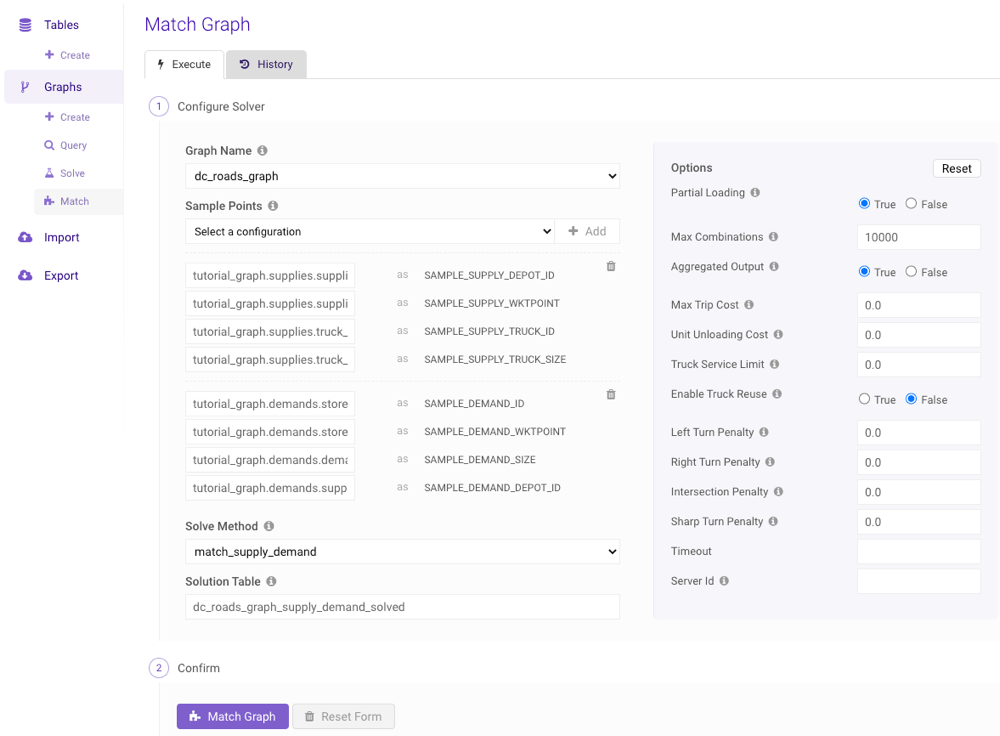
Match
An existing graph can be matched using a variety of methods by clicking Match (underneath Graphs) on the left menu to navigate to the Match Graph page. Follow the steps below to match a graph using the interface:It’s highly recommended you consult
Matching a Graph, /match/graph,
and the Match Graph examples
for information on identifiers, valid configurations, combinations,
and options before matching a graph with GAdmin. If multiple
graph servers are available, it’s also recommended you consult the
Distributed Graph Servers documentation.
- Select an existing graph from the Graph Name drop-down menu.
- Select a sample points configuration from the Sample Points drop-down menu and click Add +. For each field that appears after adding the configuration, provide a column name, expression, or raw value (as outlined in Components and Identifiers) to use with the identifier. Repeat as necessary.
- Select a solver from the Solve Method drop-down menu.
- Provide a solution table name into which the results will be output.
- Adjust the options as desired.
- Click Match Graph.