Note
This documentation is for a prior release of Kinetica. For the latest documentation, click here.
Kinetica provides a generic and extensible design of networks with the aim
of being tailored or used for various real-life applications, such as
transportation, utility, social, and geospatial. Networks comprise a graph and a
solver. A graph represents topological relationships via nodes that
are connected by edges; a solver represents the type of solution appropriate for
the issue the graph was made to illustrate.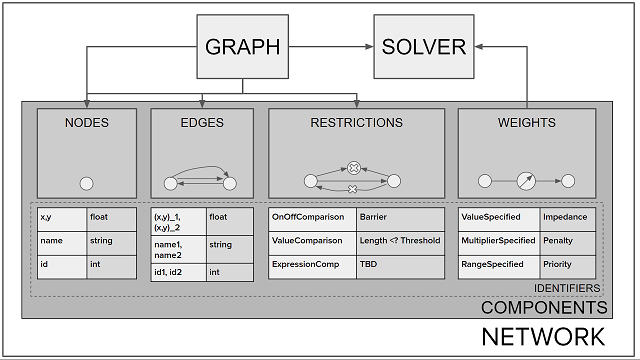
 Attempting to solve for the shortest path from node F to node A would
result in a SOLVERS_EDGE_PATH of F, E, D, C, B, A. Querying for
other nodes attached to node E would result in two adjacencies: F and
D.
Attempting to solve for the shortest path from node F to node A would
result in a SOLVERS_EDGE_PATH of F, E, D, C, B, A. Querying for
other nodes attached to node E would result in two adjacencies: F and
D.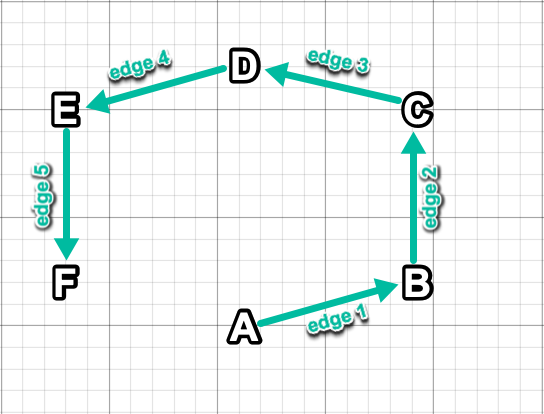


See the following supplemental briefs for details and examples:
The graph server is enabled by default. For more information
on using and configuring multiple graph servers, see
Distributed Graph Servers. Graph server logs are available in
/opt/gpudb/graph/logs. See the
Configuration Reference for more
information on graph server configuration.
Tip
Using SQL or native API, a user can create a graph from several components, solve the graph using one of several solver types, and query the solved graph.
Graphs can also be created & previewed using the
Solvers
Kinetica has several different solvers available for presenting solutions to various types of network graph problems. Note that some solvers are only available to /solve/graph and likewise for /match/graph. Consult Solving a Graph or Matching a Graph for more information on the desired operation.
Solve Graph Solvers
| Solver | Description | CPU Parallel |
|---|---|---|
| ALLPATHS | Determines all reasonable paths between a source and destination pair. | X |
| BACKHAUL_ROUTING | Determines the optimal routes between remote asset nodes and fixed asset nodes. | X |
| CENTRALITY | Calculates the degree of a node to depict how many pairs of individuals that would have to go through the node to reach one another in the minimum number of hops. Also known as betweenness. | X |
| CLOSENESS | Calculates the centrality closeness score per node as the sum of the inverse shortest path costs to all nodes in the graph. | X |
| INVERSE_SHORTEST_PATH | Determines the shortest path downstream using multiple technician routing. | X |
| MULTIPLE_ROUTING | Calculates the shortest possible route between the nodes and returns to the origin node -- also known as the traveling salesman. | X |
| PAGE_RANK | Calculates how connected the nodes are and determines which nodes are the most important. Weights are not required. | X |
| PROBABILITY_RANK | Calculates the probability of a node being connected to another node using hidden Markov chains. | X |
| SHORTEST_PATH | Determines the shortest path upstream between given source(s) and destination(s). | X |
| STATS_ALL | Calculates graph statistics such as graph diameter, longest pairs, vertex valences, topology numbers, average and max cluster sizes, etc. | X |
Match Graph Solvers
| Solver | Description | CPU Parallel |
|---|---|---|
| MARKOV_CHAIN | Matches sample points to the graph using the Hidden Markov Model (HMM)-based method, which conducts a range-tree closest-edge search to find the best combinations of possible road segments for each sample point to create the best route. The route is secured one point at a time, so the prediction is corrected after each point. This solution type is the most accurate, but also the most computationally intensive. | X |
| MATCH_BATCH_SOLVES | Matches each provided sample source and destination pair using the shortest path between the points. | X |
| MATCH_CHARGING_STATIONS | Matches a given sample source and destination pair to the optimal recharging stations along the route (for EVs). | X |
| MATCH_CLUSTERS | Matches the graph nodes with a cluster index using the Louvain clustering algorithm. Note Parallel running of this solver is experimental and can be invoked with the parallel_clustering option. | X* |
| MATCH_LOOPS | Matches closed loops (Eulerian paths) originating and ending at each graph node between min and max hops (levels). | X |
| MATCH_OD_PAIRS | Matches sample points to find the most probable path between origin and destination (OD) pairs with given cost constraints. | X |
| MATCH_SIMILARITY | Computes the Jaccard similarity between vertex pairs and N-level intersections within M hops. | X |
| MATCH_SUPPLY_DEMAND | Matches sample generic supply depots to generic demand points using abstract transportation (referred to as trucks). Each route is determined by a truck's ability (size) to service demand at each demand point. | X |
Components and Identifiers
Graph components (e.g., nodes, edges, weights, and/or restrictions) must be defined with varying combinations of the identifiers listed in the tables below.
Components for create, solve, query, and match operations can be identified in three ways:
- Aliasing existing table columns, e.g., table_name.column_name AS WKTPOINT
- Using expressions, e.g., ST_LENGTH(wkt) AS VALUESPECIFIED
- Using constant values, where strings & WKTs are single-quoted, non-decimal
numbers will be given an int or long type according to their size
(or can be coerced to long by using an L suffix, like 1L), and
decimal numbers will be given the double type; e.g.:
- {0} AS ONOFFCOMPARED
- {1L, 2, 3L, 4, 5} AS ID
- {1.1, 12.345689, 123.456789456789} AS NODE1_X
- {'name1', 'name2'} AS NAME
- {'POINT(10 15)'} AS WKTPOINT
Note
There are separate identifiers and combinations for /solve/graph, /query/graph, and /match/graph. See below for /solve/graph identifiers; see the associated Querying a Graph and Matching a Graph sections for their respective endpoint identifiers.
Identifiers are flagged aliases that the database knows to look for; existing source columns can be used as identifiers. Note that it will often be the case that source columns are reused for different identifiers because the components must naturally be linked together to create a network graph. For example, source table seattle_road_network has columns WKTLINE (a wkt column), TwoWay (an integer column), and time (also an integer column); these columns could be identified via /create/graph like so:
Create Graph Example
| |
Important
Identifiers with string as a supported type can be any string column type, e.g., char1 - char256 or unrestricted string. Identifiers with wkt as a supported type can include optional z-level values for the provided WKT shape but note that graphs only support z-levels ranging from -4 to +5.
Nodes
Nodes represent fundamental topological units of a graph. Nodes can be defined with an integer ID, a string name, or geospatial information, e.g., WKT point (POINT(X Y [Z])) or XY pair. Nodes are optional, as the start and end points of an edge can implicitly be used as nodes.
| Identifier | Supported Types | Description |
|---|---|---|
| ID | int, long | A number representing a node identifier |
| LABEL | string | A string value representing a node's label |
| NAME | string | A string value representing a node's name |
| PARTITION_BOUNDARY | long | A number representing the ID of the partition containing this node, when using explicit partitioning to segment the graph; nodes spanning partition boundaries will need to be duplicated in the source table, once for each partition in which the node will reside |
| WKTPOINT | wkt | A WKT string representing a node's geospatial point; e.g., POINT(X Y [Z]) See Geospatial Objects for more information on WKTs. |
| X | float, double, int, long | A number representing a node's X or longitude value |
| Y | float, double, int, long | A number representing a node's Y or latitude value |
Edges
Edges represent the required fundamental topological units of a graph that typically connect nodes. Edges can be defined with an integer ID, string name, or geospatial information, e.g., WKT point (POINT(X Y [Z])), line (LINESTRING(X1 Y1 [Z1], X2 Y2 [Z2])), or XY pairs. An edge can be implicitly drawn between two nodes. If an edge is defined using WKT linestrings, the graph server is capable of splitting many linestring segments into multiple, separate linestrings, thus creating one edge per linestring segment.
| Identifier | Supported Types | Description |
|---|---|---|
| ID | int, long | A number representing an edge identifier |
| DIRECTION | int | A number representing what direction the edge can be traveled:
|
| LABEL | string | A string value representing an edge's label |
| NODE1_ID | int, long | A number representing the edge's first node |
| NODE1_NAME | string | A string value representing the edge's first node's name |
| NODE1_WKTPOINT | wkt | A WKT string representing the edge's first node's geospatial point; e.g., POINT(X1 Y1 [Z1]) See Geospatial Objects for more information on WKTs. |
| NODE1_X | float, double, int, long | A number representing the edge's first node's X or longitude value |
| NODE1_Y | float, double, int, long | A number representing the edge's first node's Y or latitude value |
| NODE2_ID | int, long | A number representing the edge's second node |
| NODE2_NAME | string | A string value representing the edge's second node's name |
| NODE2_WKTPOINT | wkt | A WKT string representing the edge's second node's geospatial point; e.g., POINT(X2 Y2 [Z2]) See Geospatial Objects for more information on WKTs. |
| NODE2_X | float, double, int, long | A number representing the edge's second node's X or longitude value |
| NODE2_Y | float, double, int, long | A number representing the edge's second node's Y or latitude value |
| PARTITION | long | A number representing the ID of the partition containing this edge, when using explicit partitioning to segment the graph |
| WEIGHT_VALUESPECIFIED | float, double, int, long | A number representing the edge's associated weight value; if this identifier is provided, additional weights do not need to be specified |
| WKTLINE | wkt | A WKT string representing an edge's geospatial line; e.g., LINESTRING(X1 Y1 [Z1], X2 Y2 [Z2]) See Geospatial Objects for more information on WKTs. |
Weights
Weights represent a method of informing the graph solver of the cost of including a given edge in a solution. Weights can be defined using an integer ID, string node names, or spatial information (LINESTRING(X1 Y1 [Z1], X1 Y1 [Z1])) and a static cost value or a cost multiplier. Each edge is associated with one weight, but there can be many edges between two nodes in a graph with directionality (EDGE_DIRECTION), allowing for many different weights along the same edge, which can have useful applications in real-world examples, e.g., different lanes between two junctions may have different speeds of travel.
For graphs that define edges using complex WKT linestrings (e.g., linestrings with more than two points), weights are applied consistently to each segment of the linestring. For example, if LINESTRING(0 0, 1 3, 4 5) is provided as an edge source and a weight of 5 is assigned to that source, the resulting graph would have two edges, LINESTRING(0 0, 1 3) and LINESTRING(1 3, 4 5), that would both have a weight of 5. See Fitting Road Network Data to a Graph for more information.
Note
If DIRECTION is specified for an edge in a directed graph, the weight will be the same going in each direction.
| Identifier | Supported Types | Description |
|---|---|---|
| EDGE_DIRECTION | int | A number representing what direction the edge can be traveled:
|
| EDGE_ID | int, long | A number representing a weight's associated edge identifier |
| EDGE_NODE1_ID | int, long | A number representing a weight's associated edge's first node |
| EDGE_NODE1_NAME | string | A string value representing a weight's associated edge's first node's name |
| EDGE_NODE2_ID | int, long | A number representing a weight's associated edge's second node |
| EDGE_NODE2_NAME | string | A string value representing a weight's associated edge's second node's name |
| EDGE_PARTITION | long | A number representing a weight's associated edge's partition ID |
| EDGE_WKTLINE | wkt | A WKT string representing a weight's associated edge geospatial line; e.g., LINESTRING(X1 Y1 [Z1], X2 Y2 [Z2]) See Geospatial Objects for more information on WKTs. |
| FACTORSPECIFIED | float, double, int, long | A number representing how much incoming cost values will be multiplied |
| FROM_EDGE_ID | int, long | A number representing a weight's associated edge identifier that signifies the start of a turn; paired with TO_EDGE_ID to define additionally-weighted traversal from one edge to another through any single node Note Only applicable if the add_turns option was set to true during /create/graph. This identifier can be used to locally override any *_turn_penalty and/or intersection_penalty options previously set. See Using Turn-based Weights & Restrictions for more information. |
| TO_EDGE_ID | int, long | A number representing a weight's associated edge identifier that signifies the end of a turn; paired with FROM_EDGE_ID to define additionally-weighted traversal from one edge to another through any single node Note Only applicable if the add_turns option was set to true during /create/graph. This identifier can be used to locally override any *_turn_penalty and/or intersection_penalty options previously set. See Using Turn-based Weights & Restrictions for more information. |
| WKTPOINT | wkt | A WKT string representing a weight's associated WKT point Note Used exclusively in conjunction with FACTORSPECIFIED to create a combination for graphing weights by the inverse distance weighted averaging of WKT points composing a graph. |
| VALUESPECIFIED | float, double, int, long | A number representing the weight's value |
Important
Currently, FACTORSPECIFIED will only affect the cost if the edge has a VALUESPECIFIED already established. This means that FACTORSPECIFIED should only be used in /solve/graph or in conjunction with a VALUESPECIFIED during /create/graph.
Restrictions
Restrictions represent a method of informing the graph solver which edges and/or nodes should be ignored for the solution. Restrictions can be defined using an integer ID and a value or as a switch (on or off).
| Identifier | Supported Types | Description |
|---|---|---|
| EDGE_DIRECTION | int | A number representing what direction the edge can be traveled:
|
| EDGE_ID | int, long | A number representing the restriction's associated edge identifier |
| EDGE_LABEL | string | A string value referring to an edge label for restrictive purposes |
| EDGE_NODE1_ID | int, long | A number representing a restriction's associated edge's first node |
| EDGE_NODE1_NAME | string | A string value representing a restriction's associated edge's first node's name |
| EDGE_NODE2_ID | int, long | A number representing a restriction's associated edge's second node |
| EDGE_NODE2_NAME | string | A string value representing a restriction's associated edge's second node's name |
| EDGE_PARTITION | long | A number representing a restriction's associated edge's partition ID |
| EDGE_WKTLINE | wkt | A WKT string representing a weight's associated edge geospatial line; e.g., LINESTRING(X1 Y1 [Z1], X2 Y2 [Z2]) See Geospatial Objects for more information on WKTs. |
| FROM_EDGE_ID | int, long | A number representing the restriction's associated edge identifier that signifies the start of a turn; paired with TO_EDGE_ID to define traversal restriction from one edge to another through any single node Note Only applicable if the add_turns option was set to true during /create/graph. This identifier can be used to locally override any *_turn_penalty and/or intersection_penalty options previously set. See Using Turn-based Weights & Restrictions for more information. |
| NODE_ID | int, long | A number representing the restriction's associated node identifier |
| NODE_LABEL | string | A string value referring to a node label for restrictive purposes |
| NODE_NAME | string | A string value representing the restriction's associated node |
| NODE_WKTPOINT | wkt | A WKT string representing the restriction's associated node's geospatial point, e.g., POINT(X Y [Z]) See Geospatial Objects for more information on WKTs. |
| ONOFFCOMPARED | int | A number representing if the associated node or edge cannot be traversed, with 1 meaning it can be traversed and 0 meaning it cannot |
| TO_EDGE_ID | int, long | A number representing the restriction's associated edge identifier that signifies the end of a turn; paired with FROM_EDGE_ID to define traversal restriction from one edge to another through any single node Note Only applicable if the add_turns option was set to true during /create/graph. This identifier can be used to locally override any *_turn_penalty and/or intersection_penalty options previously set. See Using Turn-based Weights & Restrictions for more information. |
| VALUECOMPARED | float, double, int, long | A number representing the value against which incoming costs will be compared |
Note
When using VALUECOMPARED, solvers will not use the given node or edge if the current cost is less than the restriction value. When using ONOFFCOMPARED, solvers will not use the given node or edge if the ONOFFCOMPARED value is set to 0 (off).
Identifier Combinations
For each component, there's a minimum set of identifiers that must be used to properly create a graph. Each component's identifier combinations must reference columns from the same table, e.g., the node combination of ID and NAME must both use the same table. The columns must also not be nullable. Identifier types across components should match where possible.
Important
WKT identifiers can be matched to X/Y identifiers (and vice versa) within a user-specified tolerance (merge_tolerance under the /create/graph endpoint's options map). Using ID or NAME identifiers relies on exact matching. The WKTLINE identifiers will use the line's start and end points to map to an XY pair or WKTPOINT.
For example, if the identifier combination used for nodes is:
Node Identifier Combination Example
| |
The edges identifier combination should include a match for the node ID. The following edge combination would match correctly with the node combination; note that matching node point(s) to edge endpoint(s) requires two edge endpoints to make an implicit edge between the points:
Edge Identifier Combination Example
| |
Note
The above example is not the only edge combinations available for the node ID identifier combination. See the Edges section below for other combinations.
If using multiple groups of combinations while creating, solving, querying, or matching a graph, the combinations must be separated by empty quotes ("") in the respective array, e.g.:
Query Identifier Combination Example
| |
If specifying identifier combinations as raw values, the number of values within each identifier must match across the combination group, e.g.:
"{'Bill', 'Alex'} AS NODE_NAME",
"{0, 0} AS ONOFFCOMPARED"
Nodes
- ID
- ID, NAME
- ID, WKTPOINT
- ID, X, Y
- NAME
- NAME, WKTPOINT
- NAME, X, Y
- WKTPOINT
- X, Y
The following identifiers can be added to any valid node combination:
- LABEL
- PARTITION_BOUNDARY
Edges
- ID, NODE1_ID, NODE2_ID
- ID, NODE1_ID, NODE2_ID, DIRECTION
- ID, NODE1_NAME, NODE2_NAME
- ID, NODE1_WKTPOINT, NODE2_WKTPOINT
- ID, NODE1_X, NODE1_Y, NODE2_X, NODE2_Y
- ID, WKTLINE
- ID, WKTLINE, DIRECTION
- NODE1_ID, NODE2_ID
- NODE1_NAME, NODE2_NAME
- NODE1_WKTPOINT, NODE2_WKTPOINT
- NODE1_X, NODE1_Y, NODE2_X, NODE2_Y
- WKTLINE
- WKTLINE, DIRECTION
Any or all of the following identifiers can be added to any valid edge combination:
- LABEL
- PARTITION
- WEIGHT_VALUESPECIFIED
Weights
- EDGE_ID, VALUESPECIFIED
- EDGE_ID, FACTORSPECIFIED
- EDGE_WKTLINE, EDGE_DIRECTION, VALUESPECIFIED
- EDGE_WKTLINE, VALUESPECIFIED
- EDGE_WKTLINE, FACTORSPECIFIED
- EDGE_NODE1_NAME, EDGE_NODE2_NAME, VALUESPECIFIED
- EDGE_NODE1_NAME, EDGE_NODE2_NAME, FACTORSPECIFIED
- EDGE_NODE1_ID, EDGE_NODE2_ID, VALUESPECIFIED
- EDGE_NODE1_ID, EDGE_NODE2_ID, FACTORSPECIFIED
- WKTPOINT, FACTORSPECIFIED
If utilizing turn penalties, the following combination becomes applicable:
- FROM_EDGE_ID, TO_EDGE_ID, VALUESPECIFIED
Restrictions
- EDGE_ID, ONOFFCOMPARED
- EDGE_ID, VALUECOMPARED
- EDGE_LABEL, ONOFFCOMPARED
- EDGE_NODE1_ID, EDGE_NODE2_ID, ONOFFCOMPARED
- EDGE_NODE1_NAME, EDGE_NODE2_NAME, ONOFFCOMPARED
- EDGE_WKTLINE, EDGE_DIRECTION, ONOFFCOMPARED
- EDGE_WKTLINE, EDGE_DIRECTION, VALUECOMPARED
- EDGE_WKTLINE, ONOFFCOMPARED
- EDGE_WKTLINE, VALUECOMPARED
- NODE_ID, ONOFFCOMPARED
- NODE_ID, VALUECOMPARED
- NODE_LABEL, ONOFFCOMPARED
- NODE_NAME, VALUECOMPARED
- NODE_NAME, ONOFFCOMPARED
- NODE_WKTPOINT, ONOFFCOMPARED
- NODE_WKTPOINT, VALUECOMPARED
If utilizing turn restrictions, the following combination becomes applicable:
- FROM_EDGE_ID, TO_EDGE_ID, ONOFFCOMPARED
Using Labels
Labels are a type of identifier that provide additional context to a node or edge and can act as a target for a query. Labels are paired with another identifier in several valid combinations listed above, but each unique label must be part of its own combination; i.e., there cannot be two labels in the same identifier combination. For example, this is a valid multi-label configuration:
Valid Multi-Label Configuration
| |
But this example is invalid:
Invalid Multi-Label Configuration
| |
There are several types of labels, some of which can only be referenced in the context of the /query/graph endpoint. See the sections below for more information.
Node / Edge Labels
The LABEL node identifiers & edge identifiers are used to provide additional string-based information about a node or edge respectively, similarly to the node NAME (and other related) identifiers.
Restriction Labels
The NODE_LABEL and EDGE_LABEL restriction identifiers are used to restrict the value set defined as node & edge LABEL respectively. These restrictive identifiers must follow an already-defined node or edge LABEL; i.e., they cannot be used on their own at graph creation time. They are used in restriction combinations just like other restriction identifiers.
For example, if the relation between two people is used as the edge LABEL when creating a graph:
Edge Identifier Combination
| |
Then the family relation label can be restricted during the subsequent query using the EDGE_LABEL restriction identifier:
Restriction Identifier Combination Example
| |
Unique Query Labels
There are several *_LABEL query identifiers that are unique to the /query/graph endpoint.
Node / Edge Labels
The NODE_LABEL and EDGE_LABEL query identifiers are not paired with other query combinations; they are used to retrieve only the nodes and/or edges associated with a given label. For example:
Query Identifier Combination Example
| |
Target Labels
The TARGET_NODE_LABEL query identifier is always paired with another query combination to define a source-destination relationship and pathing for a query. This identifier also must follow an already-defined node LABEL. Note that an adjacency output table will have two additional columns if the TARGET_NODE_LABEL identifier is used:
- PATH_ID - an ID that helps identify the different paths taken to arrive at the query target if there is more than one adjacency for a given query.
- RING_ID - an ID that helps identify the steps taken to arrive at a query target. The RING_ID can also be referred to as the hop ID or number of hops it took to arrive at the query target
For example, a social graph can be created, representing a set of people, their primary interests, and their relationship to each other. Each node represents a person with their first name as the node NAME and the primary interest as the node LABEL, while each edge represents the relationship between each pair of people. The nodes would be defined as follows, using the name & interest columns from a table containing a given set of people as the NAME & LABEL of each node, respectively:
Node Identifier Combination
| |
This graph can be used to query for people with an interest in chess who are related either directly, or indirectly via one or more other people, to the person named Jane. This can be accomplished by querying the graph, using "Jane" as the query NODE_NAME (which instructs the graph engine to begin the search at the node with a NAME of "Jane") and using "chess" as the TARGET_NODE_LABEL (which directs the graph engine to only return directly or indirectly connected nodes with a node LABEL of "chess"):
Query Target Identifier Combination Example
| |
The query results in two targets for the output adjacency table (Alex and Tom):
Query Target Identifier Combination Results
| |
Using Turn-based Weights & Restrictions
Turn-based weights and restrictions are used to add a cost to solutions utilizing turn types implemented during graph creation or modification. If the add_turns option is set to true during /create/graph or /modify/graph operations, dummy pillowed edges will be added to each intersection of edges in a graph to mimic realistic turns. These dummy edges will not have any weight by default and will have the coordinates of their origin point. The available turn types are as follows:
- Left turns -- turning left from one edge on to another
- Right turns -- turning right from one edge on to another
- Intersection -- continuing through an intersection of edges (e.g., a stoplight)
- Sharp turns -- turning sharply left or right or a u-turn; a sharp turn or u-turn attribution is determined by the angle of the turn (the turn_angle setting)
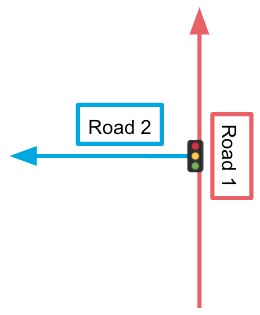
For example, say you have a dataset featuring the intersection (designated by the traffic light) below:
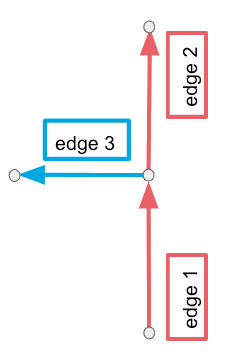
Road 1 is a one-way road going north. Road 2 is a one-way road going west. If you were to create a graph from this dataset with add_turns set to false, the edges might look like this:
A solution containing the left turn from road 1 on to road 2 using this graph would incorporate .
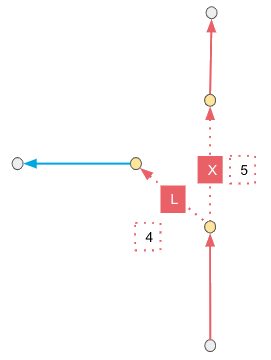
On the other hand, if you were to create a graph from this dataset with add_turns set to true, the edges might look like this instead (note the two additional dummy edges designated by the dotted lines):
The L and the X associated with the dummy edges designate a left turn and intersection respectively, but these attributions could change depending on the turn angle set. A solution containing the left turn from road 1 on to road 2 using this graph instead would incorporate .
Once turns have been enabled and the turn angle has been set, turn penalties can be incurred via the /solve/graph or the /match/graph endpoints using two methods:
Setting penalties uniformly per turn type across the graph using the left_turn_penalty, right_turn_penalty, intersection_penalty, or sharp_turn_penalty options
Setting penalties on a per-edge basis using the following weight identifier combinations:
FROM_EDGE_ID, TO_EDGE_ID, VALUESPECIFIED
Setting restrictions on a per-edge basis using the following restriction identifier combinations:
FROM_EDGE_ID, TO_EDGE_ID, ONOFFCOMPARED
Tip
Using the weight or restriction combinations will locally override any penalty options set.
For more information on using turn penalties and restrictions, see the turn penalties and restrictions graph example.
Creating a Graph
Creating a graph is serviced by the /create/graph endpoint; this involves reading from tables with annotated component identifiers and drawing relationships between given nodes and/or edges on a graph, taking into account nodes or edges between nodes that should be favored or ignored.
Note
Though it's recommended edges and weights are kept in the same table, it's not required.
Once the components are setup, the graph can be created. Requirements for creating a graph include:
- name for the graph
- if the graph is directed or not
- edges
- weights (for most solver types)
Important
Nodes and restrictions are not required to create a graph. If nodes are included, however, they should be kept in a separate table from edges and weights. If restrictions are included, they can exist in either the nodes table and/or edges/weights table(s) or in an entirely separate table.
A graph name must adhere to the standard naming criteria. Each graph exists within a schema and follows the standard name resolution rules for tables.
Directed Graphs
Whether a graph is directed or not can determine how a graph is solved or queried. Using Components and Identifiers and Identifier Combinations for context, edges connect two nodes together ("node 1" and "node 2"). When a graph is directed, these nodes that comprise a given edge have an implicit direction: "node 1" to "node 2". Regardless if these nodes have a spatial context, Kinetica will treat "node 2" as if it must be traveled to directly from "node 1" (whatever their underlying values may be: Jim and George , POINT(0 0) and POINT(9 10), 32 and 45, etc.).
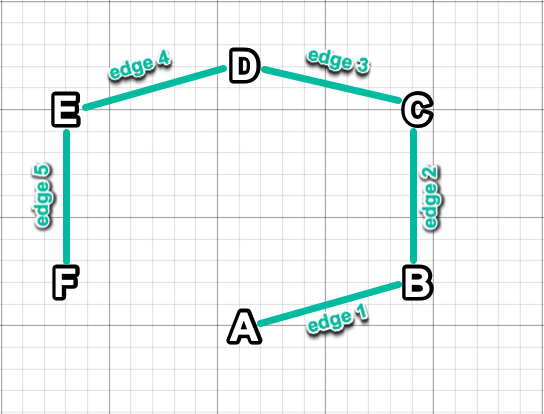
For example, given the below non-directed graph:
Attempting to solve for the shortest path from node F to node A would
result in a SOLVERS_EDGE_PATH of F, E, D, C, B, A. Querying for
other nodes attached to node E would result in two adjacencies: F and
D.
On the other hand, given the below directed graph:
Attempting to solve for the shortest path from node F to node A would be unsuccessful because there are only edges going toward F (and none leading away from F and subsequently toward A). Querying for other nodes attached to node E would result in a single adjacency: F.
Modifying a Graph
Modifying a graph is serviced by the /modify/graph endpoint; this involves using given node(s), edge(s), weight(s), restriction(s), and option(s) to update an existing graph. All parameters and options available to /modify/graph are also available to /create/graph; as such, many of the same principles apply to using /modify/graph.
Requirements for modifying a graph include:
- name for the existing graph
- components/identifiers and options used to modify the graph
Solving a Graph
Solving a graph is serviced by the /solve/graph endpoint; this involves using given source node(s), destination node(s), and any weights or restrictions from an existing graph to calculate a given solution type. Off-graph spatial locations are accepted in all solvers, with the results being corrected to snap locations. The calculated solution is then placed in a table in Kinetica; note that many concurrent solves over the same graph are possible. The source node determines from which node the graph solution routing is started; the destination node(s) determines at which node the graph solution will complete routes. Source/destination node(s) can be an ID, name, or WKT point.Requirements for solving a graph include:
- name of the graph to solve
- solution type
Important
Additional weights and restrictions beyond those defined in the graph creation stage can also be provided. Any provided weights will be added (in the case of VALUESPECIFIED) to or multiplied by (in the case of FACTORSPECIFIED) the existing weight(s). Consult Components and Identifiers for formatting and specifications.
There are several solution types to choose from:
| Solver | Description | CPU Parallel |
|---|---|---|
| ALLPATHS | Determines all reasonable paths between a source and destination pair. | X |
| BACKHAUL_ROUTING | Determines the optimal routes between remote asset nodes and fixed asset nodes. | X |
| CENTRALITY | Calculates the degree of a node to depict how many pairs of individuals that would have to go through the node to reach one another in the minimum number of hops. Also known as betweenness. | X |
| CLOSENESS | Calculates the centrality closeness score per node as the sum of the inverse shortest path costs to all nodes in the graph. | X |
| INVERSE_SHORTEST_PATH | Determines the shortest path downstream using multiple technician routing. | X |
| MULTIPLE_ROUTING | Calculates the shortest possible route between the nodes and returns to the origin node -- also known as the traveling salesman. | X |
| PAGE_RANK | Calculates how connected the nodes are and determines which nodes are the most important. Weights are not required. | X |
| PROBABILITY_RANK | Calculates the probability of a node being connected to another node using hidden Markov chains. | X |
| SHORTEST_PATH | Determines the shortest path upstream between given source(s) and destination(s). | X |
| STATS_ALL | Calculates graph statistics such as graph diameter, longest pairs, vertex valences, topology numbers, average and max cluster sizes, etc. | X |
Non-Batch Solving
Non-batch solving is utilized exclusively with every solver except for SHORTEST_PATH, in which case the length of the source and destination node lists will determine if non-batch or Batch Solving is utilized. If the source and destination lists do not match and the SHORTEST_PATH solver is specified, batch solving will be used. If the source and destination node lists match in length (and SHORTEST_PATH is the specified solver), non-batch solving will be used. This means that the first source index would only be matched with the first destination index, the second source index to the second destination index, etc.
For example, if you attempt to solve three unique sources (node_1, node_2, and node_3) to three unique destinations (dest_1, dest_2, dest_3) by only listing each source and destination once (calling /solve/graph with source_nodes set to ["node_1", "node_2", "node_3"] and destination_nodes set to ["dest_1", "dest_2", "dest_3"]), it would yield a result set like this:
+--------+--------+ | SOURCE | TARGET | +========+========+ | node_1 | dest_1 | +--------+--------+ | node_2 | dest_2 | +--------+--------+ | node_3 | dest_3 | +--------+--------+
Batch Solving
If using the SHORTEST_PATH solver, multiple sources can be routed to multiple destinations using batch solving. A batch will be defined by each unique source node visiting each destination node provided which will yield a Cartesian product.
Tip
Calculations from multiple unique sources are faster and more efficient than calculations with one unique source, but results may differ slightly between multiple unique source calculations and single unique source calculations (less than ~1% variance).
For example, if you wish to batch solve two unique sources (node_1, node_2) each routing to three unique destinations (dest_1, dest_2, dest_3), you'd list each source and each destination, noting that the solution will automatically map node_1 and node_2 to dest_1, dest_2, and dest_3 individually. A call to /solve/graph with source_nodes set to ["node_1", "node_2"] and destination_nodes set to ["dest_1", "dest_2", "dest_3"] would yield a result set like this:
+--------+--------+ | SOURCE | TARGET | +========+========+ | node_1 | dest_1 | +--------+--------+ | node_1 | dest_2 | +--------+--------+ | node_1 | dest_3 | +--------+--------+ | node_2 | dest_1 | +--------+--------+ | node_2 | dest_2 | +--------+--------+ | node_2 | dest_3 | +--------+--------+
However, if you wish to batch solve three unique sources (node_1, node_2, node_3) to three unique destinations (dest_1, dest_2, dest_3) (or n sources to n destinations for that matter), you'll need to list out all 9 combinations manually, e.g.,:
Source & Destination Node Definitions When the Lists Are the Same Size
| |
Important
Remember, if the source and destination nodes lists match in length, non-batch solving is used.
The above setup would yield a similar result set as the first example:
+--------+--------+ | SOURCE | TARGET | +========+========+ | node_1 | dest_1 | +--------+--------+ | node_1 | dest_2 | +--------+--------+ | node_1 | dest_3 | +--------+--------+ | node_2 | dest_1 | +--------+--------+ | node_2 | dest_2 | +--------+--------+ | node_2 | dest_3 | +--------+--------+ | node_3 | dest_1 | +--------+--------+ | node_3 | dest_2 | +--------+--------+ | node_3 | dest_3 | +--------+--------+
Querying a Graph
Querying a graph is serviced by the /query/graph endpoint; this involves querying a graph for adjacent nodes (if provided edges) or adjacent edges (if provided nodes) using integer IDs, names, or WKT information. Additional adjacent rings around the specified nodes can also be queried. Results can be exported to a table in Kinetica.
Requirements for querying a graph include:
- name of the graph to query
- a list of edge or node IDs, names, or WKTs to query
Important
Additional restrictions beyond those defined in the graph creation stage can also be provided. Query restrictions can utilize any of the restriction identifiers, including the unique LABEL identifiers.
Query Identifiers
Nodes or edges to be queried can be identified using any of the query-specific identifiers below.
Important
Consult Components and Identifiers and Identifier Combinations for general information on identifiers and combinations. Note that the same limitations that apply to /create/graph and /solve/graph identifiers also apply to /query/graph identifiers
| Identifier | Supported Types | Description |
|---|---|---|
| EDGE_ID | int, long | Defines the edge ID value that will be matched against in the source graph to determine the source for the query |
| EDGE_LABEL | string | Defines the edge LABEL value that will be matched against in the source graph to determine the source(s) for the query See Using Labels for more information. |
| EDGE_WKTLINE | wkt | Defines the edge WKTLINE value that will be matched against in the source graph to determine the source for the query |
| NODE_ID | int, long | Defines the node ID value that will be matched against in the source graph to determine the source for the query |
| NODE_LABEL | string | Defines the node LABEL value that will be matched against in the source graph to determine the source(s) for the query See Using Labels for more information. |
| NODE_NAME | string | Defines the node NAME value that will be matched against in the the source graph to determine the source for the query |
| NODE_WKTPOINT | wkt | Defines the node WKTPOINT value that will be matched against in the source graph to determine the source for the query |
| NODE1_ID | int, long | Defines the node ID value that will be matched against in the source graph (in conjunction with NODE2_ID) to determine the source for the query |
| NODE1_NAME | string | Defines the node NAME value that will be matched against in the source graph (in conjunction with NODE2_NAME) to determine the source for the query |
| NODE1_WKTPOINT | wkt | Defines the node WKTPOINT value that will be matched against in the source graph (in conjunction with NODE2_WKTPOINT) to determine the source for the query |
| NODE2_ID | int, long | Defines the node ID value that will be matched against in the source graph (in conjunction with NODE1_ID) to determine the source for the query |
| NODE2_NAME | string | Defines the node NAME value that will be matched against in the source graph (in conjunction with NODE1_NAME) to determine the source for the query |
| NODE2_WKTPOINT | wkt | Defines the node WKTPOINT value that will be matched against in the source graph (in conjunction with NODE1_WKTPOINT) to determine the source for the query |
| TARGET_NODE_LABEL | string | Defines the node LABEL value that will be matched against in the source graph to determine the destination for the query as well as the path taken through the graph to arrive at the destination |
Using Query Identifiers
Pair one value with an appropriate identifier to query for features connected to the given value within the provided number of rings:
Query Identifier Example (Single Key Search)
| |
Pair multiple values with a single appropriate identifier to query for features connected to each value independently (effectively an OR) within the provided number of rings:
Query Identifier Example (Multiple Key Search, X OR Y)
| |
Important
A rings value of 0 will return features that match the provided query exactly; in this case, the query would return nodes that have a label of female or chess
Providing any combination with the TARGET_NODE_LABEL identifier (separated by an empty string) will effectively produce a source-destination query where the first combination is the source and the TARGET_NODE_LABEL is the destination (assuming the destination is within the provided number of rings):
Query Identifier Example (Single Target Search)
| |
Important
Implicitly defined nodes, e.g., from graphs defined with just edges and/or weights, cannot be queried.
Query Identifier Combinations
To properly query a graph using identifiers, there's a minimum set of identifiers that must be used. Each identifier combination must reference columns from the same table, e.g., the combination NODE1_ID and NODE2_ID must both use columns from the same table. The columns must also not be nullable.
Nodes
The following combinations will query for edges adjacent to the node associated with the given information:
- NODE_ID
- NODE_LABEL
- NODE_NAME
- NODE_WKTPOINT
- TARGET_NODE_LABEL
Edges
The following combinations will query for nodes adjacent to the edge associated with the given information:
- EDGE_ID
- EDGE_LABEL
- EDGE_WKTLINE
- NODE1_ID, NODE2_ID
- NODE1_NAME, NODE2_NAME
- NODE1_WKTPOINT, NODE2_WKTPOINT
Matching a Graph
Matching a graph is serviced by the /match/graph endpoint; this involves matching a directed route implied by a given set of latitude/longitude points to an existing underlying road network graph using a given solution type. The solution is then calculated and output to two tables (consult /match/graph for more information):
- A table containing track information and the mean square error score -- the lower the number, the more accurate a match.
- A table containing the coordinate information and how it relates to the track information and segment from the underlying graph.
Requirements for matching a graph include:
- name of the graph to match
- sample points
- solution type
Solution types available:
| Solver | Description | CPU Parallel |
|---|---|---|
| MARKOV_CHAIN | Matches sample points to the graph using the Hidden Markov Model (HMM)-based method, which conducts a range-tree closest-edge search to find the best combinations of possible road segments for each sample point to create the best route. The route is secured one point at a time, so the prediction is corrected after each point. This solution type is the most accurate, but also the most computationally intensive. | X |
| MATCH_BATCH_SOLVES | Matches each provided sample source and destination pair using the shortest path between the points. | X |
| MATCH_CHARGING_STATIONS | Matches a given sample source and destination pair to the optimal recharging stations along the route (for EVs). | X |
| MATCH_CLUSTERS | Matches the graph nodes with a cluster index using the Louvain clustering algorithm. Note Parallel running of this solver is experimental and can be invoked with the parallel_clustering option. | X* |
| MATCH_LOOPS | Matches closed loops (Eulerian paths) originating and ending at each graph node between min and max hops (levels). | X |
| MATCH_OD_PAIRS | Matches sample points to find the most probable path between origin and destination (OD) pairs with given cost constraints. | X |
| MATCH_SIMILARITY | Computes the Jaccard similarity between vertex pairs and N-level intersections within M hops. | X |
| MATCH_SUPPLY_DEMAND | Matches sample generic supply depots to generic demand points using abstract transportation (referred to as trucks). Each route is determined by a truck's ability (size) to service demand at each demand point. | X |
Match Identifiers
Mapping a graph to a table requires a set of sample points. Sample points must be provided to the /match/graph endpoint using the unique identifiers below.
Important
Consult Components and Identifiers and Identifier Combinations for general information on identifiers and combinations. Note that the same limitations that apply to /create/graph and /solve/graph identifiers also apply to /match/graph identifiers
| Identifier | Supported Types | Description |
|---|---|---|
| DEMAND_ID | int, long | A number representing a demand's unique identifier |
| DEMAND_PENALTY | int, long, float, double | A number representing the cost for unloading at this site per unit unloaded, regardless of which supplier is unloading at it, and in addition to the global unloading cost per unit |
| DEMAND_REGION_ID | int, long | A number representing a demand source's unique identifier |
| DEMAND_SIZE | int, long, float | A number representing the size of the primary (or only) demand; used in demanding the supply denoted by SUPPLY_SIZE |
| DEMAND_SIZE2 | int, long, float | A number representing the size of the secondary demand; used in demanding the supply denoted by SUPPLY_SIZE2, when there are two different demand type constraints (e.g., weight & volume) |
| DEMAND_WKTPOINT | wkt | A WKT string representing a demand's geospatial source point |
| DESTINATION_WKTPOINT | wkt | A WKT string representing a sample's geospatial destination point; e.g., POINT(X Y [Z]) See Geospatial Objects for more information on WKTs. |
| ID | int, long | A number representing a sample's unique identifier |
| NAME | string | A string value representing a sample's name |
| OD_ID | int, long | A number representing an OD-pair-related sample's unique identifier |
| OD_TIME | float, double | A number representing an origin-destination (OD) pair-related sample's cost Note OD_TIME may not necessarily depict time, e.g., if the graph's weights were distance-based, OD_TIME could theoretically reflect distance as well, assuming the values are consistent with the values used to create the original weights. |
| ORIGIN_WKTPOINT | wkt | A WKT string representing a sample's geospatial origin point; e.g., POINT(X Y [Z]) See Geospatial Objects for more information on WKTs. |
| PRIORITY | int | A number representing a sample's priority in match processing |
| SUPPLY_ID | int, long | A number representing a supplier's unique identifier |
| SUPPLY_ODDEVEN | int | A number representing whether the supplier is "odd", "even", or neither; used in applying odd/even-based restrictions, such as those used in Jakarta, Indonesia:
|
| SUPPLY_PENALTY | int, long, float, double | A number representing the cost for unloading this supplier per unit unloaded, regardless of which demand site it is visiting, and in addition to the global unloading cost per unit |
| SUPPLY_REGION_ID | int, long | A number representing a supplier source's unique identifier |
| SUPPLY_SIZE | int, long, float | A number representing a supplier's primary (or only) capacity; used in meeting the demand denoted by DEMAND_SIZE |
| SUPPLY_SIZE2 | int, long, float | A number representing a supplier's secondary capacity; used in meeting the demand denoted by DEMAND_SIZE2, when there are two different capacity type constraints (e.g., weight & volume) |
| SUPPLY_WKTPOINT | wkt | A WKT string representing a supplier's geospatial source point |
| TIME | long, double | A number representing a sample's time value Note TIME could theoretically represent any time unit (seconds, minutes, epoch, etc.) as long as the representations are consistent for the column in the source table. |
| TRIPID | int, long | A number representing a unique trip identifier |
| WKTPOINT | wkt | A WKT string representing a sample's geospatial point; e.g., POINT(X Y [Z]) See Geospatial Objects for more information on WKTs. |
| X | float, double | A number representing a sample's X or longitude value |
| Y | float, double | A number representing a sample's Y or latitude value |
Note
Records with a timestamp of 0 for the TIME column will be ignored when calculating the solution.
Match Identifier Combinations
To properly match a graph using identifiers, there's a minimum set of identifiers that must be used. Each identifier combination must reference columns from the same table, e.g., the combination WKTPOINT and TIME must both use columns from the same table. The columns must also not be nullable. The valid match identifier combinations per match graph solver are as follows:
Markov Chain
- X, Y, TIME
- WKTPOINT, TIME
- X, Y, TIME, TRIPID
- WKTPOINT, TIME, TRIPID
Note
If using the TRIPID identifier to match the graph, all trip IDs will be used in the solution.
Match Batch Solves
- ORIGIN_WKTPOINT, DESTINATION_WKTPOINT, OD_ID
Match Loops
- ID
- NAME
- WKTPOINT
Note
Using no identifier combination will result in loops being searched for across the entire graph
Match OD Pairs
- ORIGIN_WKTPOINT, DESTINATION_WKTPOINT, OD_TIME
- ORIGIN_WKTPOINT, DESTINATION_WKTPOINT, OD_TIME, OD_ID
Match Supply Demand
A supply and demand combination are used in conjunction with each other to match suppliers to demand. Reference Identifier Combinations for using multiple combinations syntax.
Demand Combinations
- DEMAND_ID, DEMAND_WKTPOINT, DEMAND_SIZE, DEMAND_REGION_ID
- DEMAND_ID, DEMAND_WKTPOINT, DEMAND_SIZE, DEMAND_REGION_ID, PRIORITY
Any or all of the following identifiers can be added to a demand combination:
- DEMAND_PENALTY
- DEMAND_SIZE2 (must be paired with a supply combination using SUPPLY_SIZE2 )
Supply Combinations
- SUPPLY_REGION_ID, SUPPLY_WKTPOINT, SUPPLY_ID, SUPPLY_SIZE
Any or all of the following identifiers can be added to a supply combination:
- SUPPLY_ODDEVEN
- SUPPLY_PENALTY
- SUPPLY_SIZE2 (must be paired with a demand combination using DEMAND_SIZE2 )
Showing a Graph
Using /show/graph will provide detailed information about a graph, including number of nodes and edges in the graph, whether the graph is directed or persisted, and more.
Workbench also provides a mechanism to view all graphs, and map geospatial graphs.
Deleting a Graph
Deleting a graph is serviced by the /delete/graph endpoint; this involves providing a graph name to delete the graph from the graph server (memory) and persist (if applicable).
Tip
If a graph was saved to persist upon creation and then was deleted from the server (but NOT persist), it can be reloaded from persist by recreating the graph using the same graph_name.
Managing Permissions for a Graph
Graph permissions can be managed either through SQL or through the native API.
Examples
For detailed usage of the graph capability, see AWS Guides:
Limitations and Cautions
- Groups of valid identifier combinations must be from the same table, e.g., node ID & NAME must reference columns from the same table
- Node, edge, weight, and optional restriction identifiers should be matched to yield a useful graph ( and , etc.)
- Groups of valid numerical identifier combinations must be the same type, e.g., if edge ID is identified from an int column, both edge NODE1_ID & NODE2_ID must also be int
- Graphs cannot be created using columns with the nullable property
- If no ID identifier is provided, weights will be matched with edges by table row, e.g., the first record in the weight table will be used for the first record in the edge table (should the weights and edges be separate). If two weights are specified for the same edge, the weights are added (if both are using the VALUESPECIFIED identifier) or multiplied (if one or both are using the FACTORSPECIFIED identifier) together.
- A node or edge can have up to 64 unique labels.